构建多智能体AI🤖👱🏼🤖-第二章-LangGraph构建Agent智能体
一、使⽤LangGraph构建Agent智能体
这⼀章节开始,我将使⽤LangGraph来重新构建⼀个专属的聊天机器⼈。并以此为案例,逐步构建⼀个功能强⼤、⼜安全可控的聊天Agent智能体。再以此为基础,为后续LangGraph构建多智能体提供基础⽀撑。
使⽤LangGraph构建Agent智能体
Agent智能体增加Tools⼯具调⽤机制
Agent智能体消息记忆管理功能
Human-In-Loop⼈类监督功能
说明:LangGraph是和LangChain⼀体的,所以,后续内容设计都是在LangChain的基础上构建
1.1 什么是Agent?
这个问题并没有标准答案。⽽LangGraph给我们勾勒出了⼀个好的Agent智能体的形象。这个Agent,可以类⽐于⼀个好的员⼯。什么是好的员⼯呢?⾃然是希望这个员⼯即能⼒强⼤,可以放⼼的独⽴完成任务,⽽不⽤过多⼲预实现的细节。同时,这个员⼯⼜要⼜能够听从安排,关键节点要及时跟领导请示,并及时的根据领导的指示调整⾃⼰的⼯作进度。
具体到LangGraph的实现中,Agent即需要拥有封装与⼤模型交互的所有基础能⼒,包括访问⼤模型、调⽤Tools、保存ChatMemory等等这些基础的能⼒。可以独⽴的完成⼀系列基于⼤模型构建的任务。同时,我⼜可以随时⼲预Agent执⾏进度,对关键步骤随时做出调整。
1.2 构建聊天Agent智能体
要如何构建这样强⼤并且听话的Agent智能体呢?我们先从基础的⼤模型聊天开始。
在LangChain中,提供了ChatModels的接⼝,⽤于访问⼤模型。我们可以通过调⽤ChatModels的接⼝来访问⼤模型。
from langchain_community.chat_models import ChatTongyi
# 构建阿里云百炼大模型客户端
llm = ChatTongyi(
model="qwen-plus",
api_key="key",
)
llm.invoke("你是谁?能帮我解决什么问题?")⽽LangGraph只要将这个ChatModel进⾏简单的封装,就可以完成与⼤模型的交互。
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(
model=llm,
tools=[],
prompt="You are a helpful assistant",
)
agent.invoke({"messages":[{"role":"user","content":"你是谁?能帮我解决什么问题?"}]})当然,Agent也⽀持常⽤的Stream流式输出的⽅式。
for chunk in agent.stream(
{"messages":[{"role":"user","content":"你是谁?能帮我解决什么问题?"}]},
# stream_mode="messages"
):
print(chunk)
print("\n")这⾥stream_mode有三种选项:
updates : 流式输出每个⼯具调⽤的每个步骤。
messages: 流式输出⼤语⾔模型回复的Token。
values: ⼀次拿到所有的chunk。默认值。
custom : ⾃定义输出。主要是可以在⼯具内部使⽤get_stream_writer获取输⼊流,添加⾃定义的内容。
关于流式输出的这⼏种选项,在后⾯结合Graph,会体现出更⼤的作⽤。
二、增加Tools工具调用
Tools⼯具机制是⼤语⾔模型中的⼀个重要机制,它可以让⼤模型调⽤外部⼯具,从⽽实现更加复杂的功能。通常,⼀个完整的⼯具调⽤流程需要以下⼏个步骤:
客户端定义⼯具类,实现⼯具的功能。
客户端请求⼤语⾔模型,带上问题以及⼯具的描述信息。
⼤语⾔模型综合判断问题,并决定是否调⽤⼯具。
如果⼤语⾔模型判断需要使⽤⼯具,就会向客户端返回⼀个带有tool_calls⼯具调⽤信息的AiMessage。
客户端根据⼯具调⽤信息,调⽤⼯具,并将结果返回给⼤语⾔模型。
⼤语⾔模型根据⼯具调⽤的结果,⽣成最终的回答。
使⽤LangChain,我们需要实现完整的流程。⽽使⽤LangGraph后,⼯具成了Agent的标配。只需要定义⼯具类,Agent中会⾃⾏完成⼯具调⽤的流程。
import datetime
from langgraph.prebuilt import create_react_agent
def get_current_date():
"""获取今天⽇期"""
return datetime.datetime.today().strftime("%Y-%m-%d")
agent = create_react_agent(
model=llm,
tools=[get_current_date],
prompt="You are a helpful assistant",
)
agent.invoke({"messages":[{"role":"user","content":"今天是⼏⽉⼏号"}]})从返回的结果就能看到,LangGraph的Agent完整的封装了⼯具调⽤的整个流程。⽽我们所需要关注的,只是构建出带有⼯具信息的Agent,然后把⽤户的问题交给Agent去处理就⾏了。
在定义⼯具时,除了可以从⼯具函数的注释中获取⼯具描述信息外,LangGraph也同样兼容了LangChain中使⽤@tool注解声明⼯具的⽅式。
如果⼯具执⾏时出错了,LangGraph也提供了主动处理异常信息的能⼒。
from langchain_core.tools import tool
from langgraph.prebuilt import ToolNode
# 定义⼯具 return_direct=True 表示直接返回⼯具的结果
@tool("devide_tool",return_direct=True)
def devide(a : int,b : int) -> float:
"""计算两个整数的除法。
Args:
a (int): 除数
b (int): 被除数
"""
# ⾃定义错误
if b == 1:
raise ValueError("除数不能为1")
return a/b
print(devide.name)
print(devide.description)
print(devide.args)
# 定义⼯具调⽤错误处理函数
def handle_tool_error(error: Exception) -> str:
"""处理⼯具调⽤错误。
Args:
error (Exception): ⼯具调⽤错误
"""
if isinstance(error, ValueError):
return "除数为1没有意义,请重新输⼊⼀个除数和被除数。"
elif isinstance(error, ZeroDivisionError):
return "除数不能为0,请重新输⼊⼀个除数和被除数。"
return f"⼯具调⽤错误:{error}"
tool_node = ToolNode(
[devide],
handle_tool_errors=handle_tool_error
)
agent_with_error_handler = create_react_agent(
model=llm,
tools=tool_node
)
result = agent_with_error_handler.invoke({"messages":[{"role":"user","content":"10除以2等于多少?"}]})
# 打印最后的返回结果
# print(result["messages"][-1]. )
print(result)三、增加消息记忆
对⼤模型的交互信息进⾏保存,这是实现多轮对话的关键。
在LangChain中,我们需要⾃⾏定义ChatMessageHistory,并且⾃⾏保存每⼀轮的消息记录,然后在调⽤⼤模型时,将其作为参数传⼊。
LangGraph中,实现消息记录的流程,也完整的封装到了Agent当中。
LangGraph将消息记忆分为了短期记忆与⻓期记忆。
短期记忆是指Agent内部的记忆,⽤于当前对话中的历史记忆信息。LangGraph将他封装成CheckPoint
⻓期记忆是指Agent外部的记忆,⽤第三⽅存储⻓久的保存⽤户级别或者应⽤级别的聊天信息。LangGraph将它封装成Store
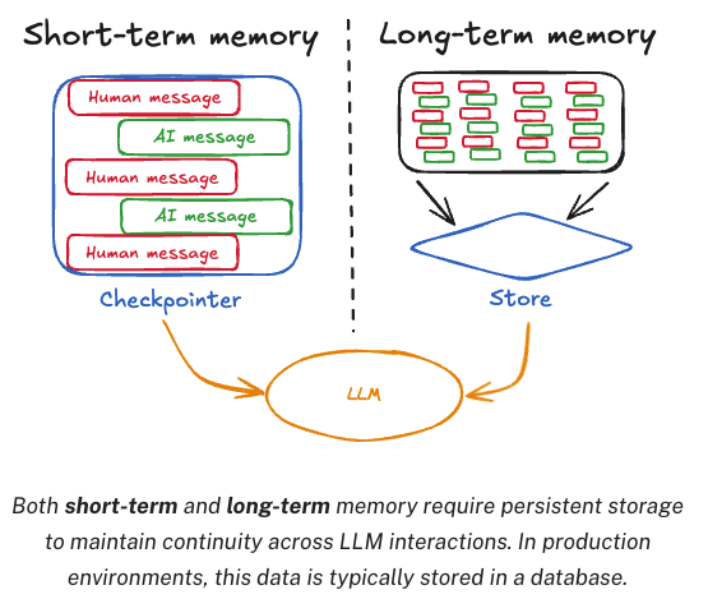
对于记忆管理,我认为LangGraph的管理⽅式或许⽐具体实现更有参考价值。
在具体实现时,LangGraph都默认提供了InMemorySaver和InMemoryStore,也同样都可以转移到其他外部存储当中。不过,短期记忆通常是代表那些会话级别的⼩内存,⽽⻓期记忆通常是代表那些⽤户级别或者应⽤级别的⼤内存。
短期记忆的内存⽐较紧张,所以需要更频繁的清理内存,并对已有的消息记录进⾏总结,从而减少内存占⽤。而⻓期记忆的内存⽐较充⾜,所以不太需要频繁的清理内存。更需要关注的,是如何对已有的消息进行检索。
3.1 短期记忆 CheckPoint
在LangGraph的Agent中,只需要指定checkpointer属性,就可以实现短期记忆。具体传⼊的属性需要是*BaseCheckpointSaver*的⼦类。
LangGraph中默认提供了InMemorySaver,⽤于将短期记忆信息保存在内存中。当然,也可以采⽤Redis、SQLite等第三⽅存储来实现⻓期记忆。不过当前版本的LangGraph并没有提供具体的实现,需要⾃⾏实现。(如果不会写,交给AI)
另外,使⽤checkpointer时,需要制定⼀个单独的thread_id来区分不同的对话。
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.prebuilt import create_react_agent
checkpointer = InMemorySaver()
def get_weather(city: str) -> str:
"""获取某个城市的天⽓"""
return f"城市:{city},天⽓⼀直都是晴天!"
agent = create_react_agent(
model=llm,
tools=[get_weather],
checkpointer=checkpointer
)
# Run the agent
config = {
"configurable": {
"thread_id": "1"
}
}
cs_response = agent.invoke(
{"messages": [{"role": "user", "content": "⻓沙天⽓怎么样?"}]},
config
)
print(cs_response)
# Continue the conversation using the same thread_id
bj_response = agent.invoke(
{"messages": [{"role": "user", "content": "北京呢?"}]},
config
)
bj_response从结果可以看到,当前会话当中和⼤模型的每次交互记录,包括⼯具调⽤的信息,都保存在了短期记忆当中。当然,⽬前的实现是保存在内存中,所以程序结束后就释放了。⽣产环境中,LangGraph建议是保存到外部存储当中,例如数据库、⽂件系统等。这样每次启动程序时,都可以从外部存储中加载历史记录。
短期记忆通常认为是⽐较紧张的,所以需要定期做清理,防⽌历史消息过多。LangGraph的Agent中,提供了⼀个pre_model_hook属性,可以在每次调⽤⼤模型之前触发。通过这个hook,就可以来定期管理短期记忆。
LangGraph中管理短期记忆的⽅法主要有两种:
Summarization 总结:⽤⼤模型的⽅式,对短期记忆进⾏总结,然后再把总结的结果作为新的短期记忆。
Trimming 删除:直接把短期记忆中最旧的消息删除掉。
LangGraph提供了SummarizationNode函数,⽤于使⽤⼤模型的⽅式对短期记忆进⾏总结。
from langmem.short_term import SummarizationNode
from langchain_core.messages.utils import count_tokens_approximately
from langgraph.prebuilt import create_react_agent
from langgraph.prebuilt.chat_agent_executor import AgentState
from langgraph.checkpoint.memory import InMemorySaver
from typing import Any
# 使⽤⼤模型对历史信息进⾏总结
summarization_node = SummarizationNode(
token_counter=count_tokens_approximately,
model=llm,
max_tokens=384,
max_summary_tokens=128,
output_messages_key="llm_input_messages",
)
class State(AgentState):
# 注意:这个状态管理的作⽤是为了能够保存上⼀次总结的结果。这样就可以防⽌每次调⽤⼤模型时,都要重新总结、历史信息。
# 这是⼀个⽐较常⻅的优化⽅式,因为⼤模型的调⽤是⽐较耗时的。
context: dict[str, Any]
checkpointer = InMemorySaver()
agent = create_react_agent(
model=llm,
# tools=tools,
pre_model_hook=summarization_node,
state_schema=State,
checkpointer=checkpointer,
)另外,还提供了trim_messages函数,⽤于定期清理短期记忆。
from langchain_core.messages.utils import (
trim_messages,
count_tokens_approximately
)
from langgraph.prebuilt import create_react_agent
# This function will be called every time before the node that calls LLM
def pre_model_hook(state):
trimmed_messages = trim_messages(
state["messages"],
strategy="last",
token_counter=count_tokens_approximately,
max_tokens=384,
start_on="human",
end_on=("human", "tool"),
)
return {"llm_input_messages": trimmed_messages}
checkpointer = InMemorySaver()
agent = create_react_agent(
model=llm,
tools=[],
pre_model_hook=pre_model_hook,
checkpointer=checkpointer,
)
```
实现了基础的短期记忆管理后,LangGraph还提供了状态管理机制,⽤于保存处理过程中的中间结果。⽽且,这些状态数据,还可以在Tools⼯具中使⽤。
```python
from typing import Annotated
from langgraph.prebuilt import InjectedState, create_react_agent
from langgraph.prebuilt.chat_agent_executor import AgentState
from langchain_core.tools import tool
class CustomState(AgentState):
user_id: str
@tool(return_direct=True)
def get_user_info(
state: Annotated[CustomState, InjectedState]
) -> str:
"""查询⽤户信息."""
user_id = state["user_id"]
return "user_123⽤户的姓名:元仔。" if user_id == "user_123" else "未知⽤户"
agent = create_react_agent(
model=llm,
tools=[get_user_info],
state_schema=CustomState,
)
agent.invoke({
"messages": "查询⽤户信息",
"user_id": "user_123"
})3.2 长期记忆
⻓期记忆通常认为是⽐较充⾜的记忆空间,因此使⽤时,可以⽐短期记忆更加粗犷,不太需要实时关注内存空间⼤⼩。
⾄于使⽤⽅式,和短期记忆差不太多。主要是通过Agent的store属性指定⼀个 实现类就可以了。与短期记忆最⼤的区别在于,短期记忆通过thread_id来区分不同的对话,⽽⻓期记忆则通过namespace来区分不同的命名空间。
from langchain_core.runnables import RunnableConfig
from langgraph.config import get_store
from langgraph.prebuilt import create_react_agent
from langgraph.store.memory import InMemoryStore
from langchain_core.tools import tool
# 定义⻓期存储
store = InMemoryStore()
# 添加⼀些测试数据。 users是命名空间,user_123是key,后⾯的JSON数据是value
store.put(
("users",),
"user_123",
{
"name": "元仔",
"age": "23",
}
)
#定义⼯具
@tool(return_direct=True)
def get_user_info(config: RunnableConfig) -> str:
"""查找⽤户信息"""
# 获取⻓期存储。获取到了后,这个存储组件可读也可写
store = get_store()
# store.put(
# ("users",),
# "user_456",
# {
# "name": "楼兰",
# "age": "33",
# }
# )
# 获取配置中的⽤户ID
user_id = config["configurable"].get("user_id")
user_info = store.get(("users",), user_id)
return str(user_info.value) if user_info else "Unknown user"
agent = create_react_agent(
model=llm,
tools=[get_user_info],
store=store
)
# Run the agent
agent.invoke(
{"messages": [{"role": "user", "content": "查找⽤户信息"}]},
config={"configurable": {"user_id": "user_123"}}
)四、Human-in-the-loop 人类监督
这也是LangGraph的Agent中⾮常核⼼的⼀个功能。
在Agent的⼯作过程中,有⼀个问题是⾮常致命的。就是Agent可以添加Tools⼯具,但是要不要调⽤⼯具,却完全是由Agent⾃⼰决定的。
这就会导致Agent在⾯对⼀些问题时,可能会出现错误的判断。
为了解决这个问题,LangGraph提供了Human-in-the-loop的功能。在Agent进⾏⼯具调⽤的过程中,允许⽤户进⾏监督。这就需要中断当前的执⾏任务,等待⽤户输⼊后,再重新恢复任务。
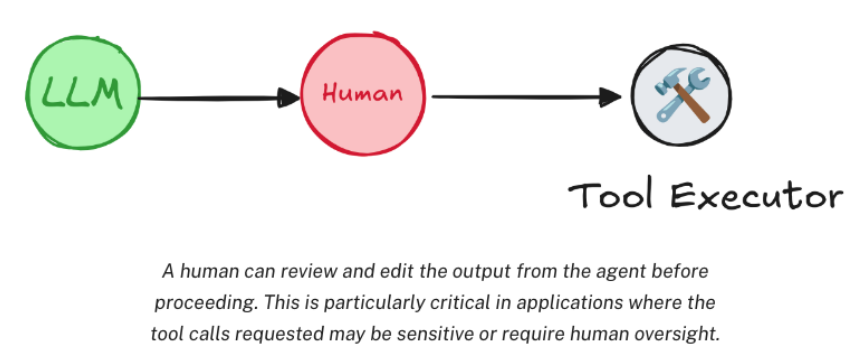
在实现时,LangGraph提供了interruput()⽅法添加⼈类监督。监督时需要中断当前任务,所以通常是和stream流式⽅法配合使⽤。
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import interrupt
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
# An example of a sensitive tool that requires human review / approval
@tool(return_direct=True)
def book_hotel(hotel_name: str):
"""预定宾馆"""
response = interrupt(
f"正准备执⾏'book_hotel'⼯具预定宾馆,相关参数名: {{'hotel_name': {hotel_name}}}. "
"请选择OK,表示同意,或者选择edit,提出补充意⻅."
)
if response["type"] == "OK":
pass
elif response["type"] == "edit":
hotel_name = response["args"]["hotel_name"]
else:
raise ValueError(f"Unknown response type: {response['type']}")
return f"成功在 {hotel_name} 预定了⼀个房间."
checkpointer = InMemorySaver()
agent = create_react_agent(
model=llm,
tools=[book_hotel],
checkpointer=checkpointer,
)
config = {
"configurable": {
"thread_id": "1"
}
}
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "帮我在元仔宾馆预定⼀个房间"}]},
config
):
print(chunk)
print("\n")执⾏完成后,会在book_hotel执⾏过程中,输出⼀个Interrupt响应,表示当前正在等待⽤户输⼊确认。
接下来,可以通过Agent提交⼀个Command请求,来继续完成之前的任务。
需要注意的是,在这个示例中,Agent只会⼀直等待⽤户输⼊。如果等待时间过⻓,后续请求就⽆法恢复了。
from langgraph.types import Command
for chunk in agent.stream(
# Command(resume={"type": "OK"}),
Command(resume={"type": "edit", "args": {"hotel_name": "三号宾馆"}}),
config
):
print(chunk)
print(chunk['tools']['messages'][-1].content)
print("\n")五、LangGraph的Agent总结
Agent,这是LangGraph后续构建Graph图的基础。但其实Agent并不是LangGraph框架当中独有的。甚⾄Agent并不是⼀种技术,而是我设想的⼀种理想的⼤模型⼯作模式。那么到底什么是Agent?或者说AI⾏业⼼⽬中理想的Agent应该是什么样⼦呢?LangGraph实际上给我们提供了⼀种理解。⽽这个理解,或许⽐具体实现更重要。
上面的章节介绍了LangGraph的Agent功能,以及如何使⽤LangGraph的Agent功能来构建⼀个简单的应⽤。对于LangGraph框架来说,由于有了LangChain作为⽀撑,Agent智能体或许并不是他的重点。后续,LangGraph使⽤Graph图的⽅式协调管理多个Agent,或许是更⼤的价值所在。
使⽤LangGraph构建Agent智能体
Agent智能体增加Tools⼯具调⽤机制
Agent智能体消息记忆管理功能
Human-In-Loop⼈类监督功能
但是,LangGraph对于Agent的功能封装却给⼤模型应⽤落地提供了⾮常好的思想指导。通过Agent,我不再需要关注应⽤的实现细节,而是可以更专注于应⽤的功能设计。⽽Agent,绝不仅仅只是LangGraph所需要构建的,即便脱离LangGraph框架,如何构建⼀个能⼒强⼤⼜听话懂事的Agent,或许是我后续都需要思考的问题。
六、LangGraph接入MCP
在2024年底,claude⼤模型的开发公司Anthropic提出了⼀个MCP(Model Context Protocol)协议。通过MCP协议,可以让应⽤程序以⼀种统⼀的⽅式向LLM⼤语⾔模型提供⼯具调⽤。
⽽随着⼏千个MCP服务突然冒出,百度、阿⾥等⼚商也开始⼤规模接⼊MCP,这个协议也迅速在互联⽹上引起轩然⼤波。按照那些流量派⻅⻛就是⾬的性⼦,MCP也着实被⼤吹特吹了⼀波。随着MCP服务越来越⽕爆,LangGraph的Agent中也提供了MCP的集成。这次我就分⼏个部分,逐步深度拆解MCP服务。
MCP快速上⼿
理解MCP的stdio和sse两种实现模式
LangGraph的Agent接⼊MCP服务
补充:⾃⼰开发⼀个MCP服务
6.1、MCP快速上手
MCP最神奇的地⽅就是只要做下简单的配置,就能完成很多复杂的⼯作。那这次,我就先不来介绍MCP那些花⾥胡哨的概念,直接上⼿来玩玩MCP。
⾸先,我们需要使⽤⼀个⽀持MCP的客户端⼯具。 这类⼯具现在有很多,以后肯定也会越来越多。这次我们使⽤⼀个免费的。 在VSCode中有⼀个开发插件,Cline。通过这个插件可以快速和AI⼤模型交互。
安装VSCode和Cline过程略。需要稍微注意下的是,cline插件默认是访问Claude⼤模型。使⽤Cline需要先登录。登录时,可以使⽤google邮箱或者github账号登录。
然后,对Cline插件进⾏配置,让他访问国内的模型,这样就不需要科学上⽹了。
以⾼德地图提供的MCP服务为例。⾼德地图开放平台提供了⾮常详细的MCP接⼊介绍: https://lbs.amap.com/api/mcp-server/summary。 只需要在⾼德开放平台注册账号,登录后,在左侧菜单中选择“应⽤管理”->“我的应⽤”,然后创建新应⽤,就可以申请⼀个API-KEY:
有了这个API-KEY之后,在MCP Server按钮的右侧,选择MCP Server。在MCP的配置⽂件中写⼊以下内容:
name: Gaode amap-amap-sse MCP server
version: 0.0.1
schema: v1
mcpServers:
- name: amap-amap-sse
command: npx
args:
- -y
- "@amap/amap-maps-mcp-server" # 这里保留了引号,确保 @ 符号被正确解析
env:
AMAP_MAPS_API_KEY: "key" # 使用正确的键值对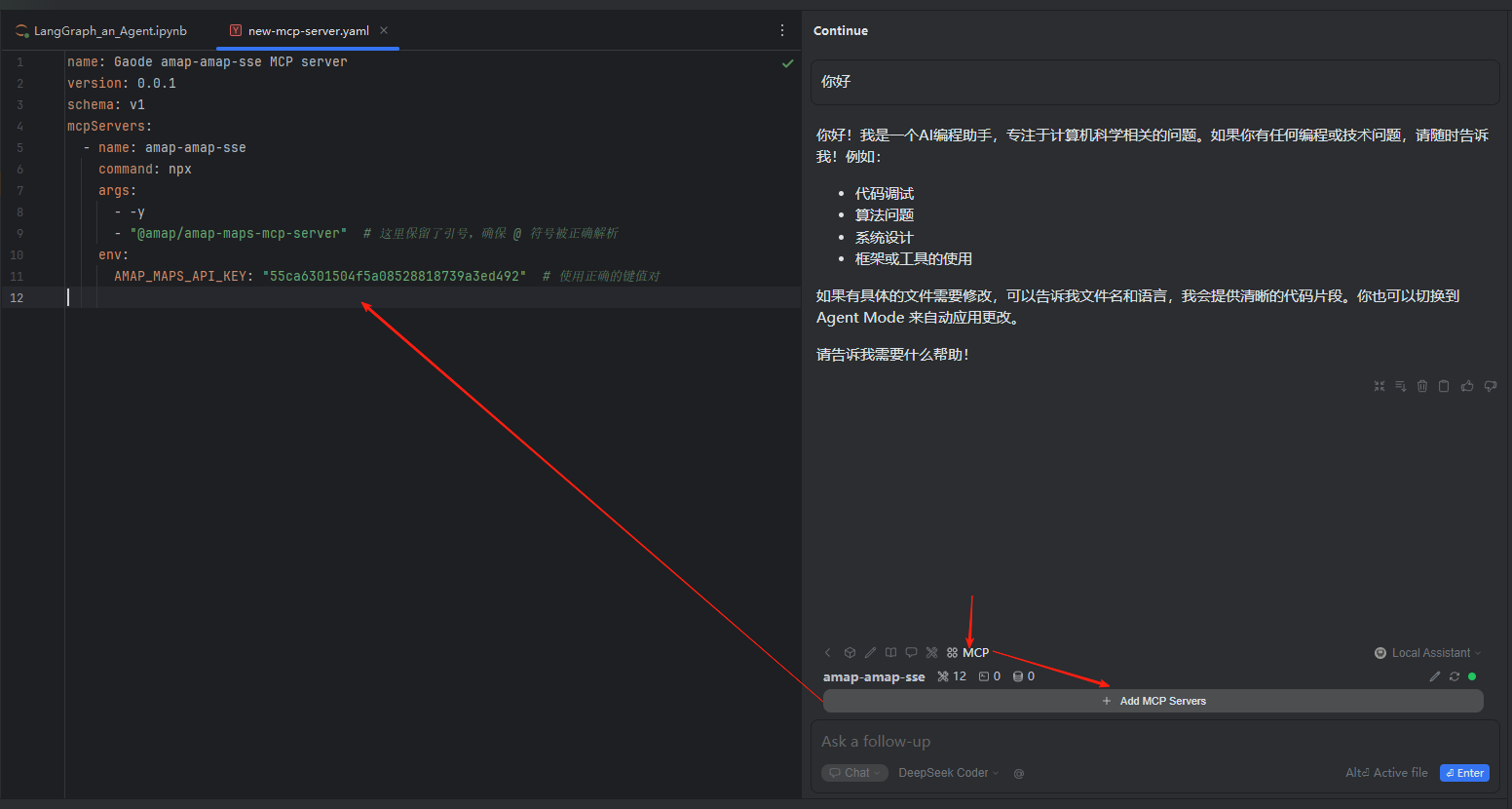
配置完成,右侧就能看到这个MCP服务被安装上来了。
接下来,在Continue或者Lingma中,如果你询问和地图相关的⼀些问题,那么,Continue或者Lingma在调⽤⼤模型的过程中,就会⾃动调⽤⾼德地图的MCP服务,获得地图相关的信息。
6.2、详细梳理MCP工作机制
MCP协议,全程Model Context Protocol,中⽂翻译是模型上下⽂协议。MCP协议是由Anthropic公司提出的,是⼀个专⻔⽤于与AI⼤语⾔模型进⾏交互的协议。但是本质上,MCP协议只是允许应⽤程序以⼀种统⼀的⽅式向⼤语⾔模型提供Function call函数调⽤。⽽Function call是很多⼤语⾔模型⾃身就提供的⼀种功能机制。
例如,通过下⾯的案例,我们就可以很简单的给⼤模型提供路线规划的能⼒。
from langchain_openai import ChatOpenAI
# 构建阿⾥云百炼⼤模型客户端
llm = ChatOpenAI(
model="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="key",
)
import datetime
from langchain.tools import tool
# 定义⼯具 注意要添加注释
@tool(description="规划⾏⻋路线")
def get_route_plan(origin_city:str,target_city:str):
"""规划⾏⻋路线
Args:
origin_city: 出发城市
target_city: ⽬标城市
"""
result = f"从城市 {origin_city} 出发,到⽬标城市 {target_city} ,使⽤意念传送,只需要三分钟即可到达。"
print(">>>> get_route_plan >>>>>"+result)
return result
# ⼤模型绑定⼯具
llm_with_tools = llm.bind_tools([get_route_plan])
# ⼯具容器
all_tools = {"get_route_plan": get_route_plan}
# 把所有消息存到⼀起
query = "帮我规划⼀条从⻓沙到桂林的⾃驾路线"
messages = [query]
# 询问⼤模型。⼤模型会判断需要调⽤⼯具,并返回⼀个⼯具调⽤请求
ai_msg = llm_with_tools.invoke(messages)
print(ai_msg)
messages.append(ai_msg)
# 打印需要调⽤的⼯具
print(ai_msg.tool_calls)
if ai_msg.tool_calls:
for tool_call in ai_msg.tool_calls:
selected_tool = all_tools[tool_call["name"].lower()]
tool_msg = selected_tool.invoke(tool_call)
messages.append(tool_msg)
llm_with_tools.invoke(messages).content询问⼤模型嘛。每次询问的结果都是不⼀样的。这⾥⼀次典型的执⾏结果是这样的:
content='' additional_kwargs={'tool_calls': [{'id': 'call_a0911f133c7c4b388c840a', 'function': {'arguments': '{"origin_city": "长沙", "target_city": "桂林"}', 'name': 'get_route_plan'}, 'type': 'function', 'index': 0}], 'refusal': None} response_metadata={'token_usage': {'completion_tokens': 28, 'prompt_tokens': 180, 'total_tokens': 208, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-bb00ee50-8618-9653-9edf-b4c82c67e5c4', 'service_tier': None, 'finish_reason': 'tool_calls', 'logprobs': None} id='run--b4adffc1-7887-40cf-b203-81e1f114335f-0' tool_calls=[{'name': 'get_route_plan', 'args': {'origin_city': '长沙', 'target_city': '桂林'}, 'id': 'call_a0911f133c7c4b388c840a', 'type': 'tool_call'}] usage_metadata={'input_tokens': 180, 'output_tokens': 28, 'total_tokens': 208, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
[{'name': 'get_route_plan', 'args': {'origin_city': '长沙', 'target_city': '桂林'}, 'id': 'call_a0911f133c7c4b388c840a', 'type': 'tool_call'}]
>>>> get_route_plan >>>>>从城市 长沙 出发,到⽬标城市 桂林 ,使⽤意念传送,只需要三分钟即可到达。
'从长沙到桂林的自驾路线如下:\n\n1. **出发地:长沙**\n2. **目的地:桂林**\n\n### 推荐路线:\n- **路线1(常用路线,较平稳)**:\n - 从长沙出发,走 **沪昆高速(G60)**。\n - 经过 **怀化**,进入广西境内。\n - 继续沿 **桂林方向** 行驶,最终抵达桂林市区。\n\n- **路线2(风景优美,适合慢行)**:\n - 从长沙出发,走 **二广高速(G55)**。\n - 经过 **邵阳**、**永州**,进入广西。\n - 沿 **桂阳高速** 和 **包茂高速** 行驶,最终抵达桂林。\n\n### 总里程:\n- 大约 **700-750公里**,根据具体路线选择可能会有所不同。\n\n### 预计耗时:\n- 正常行驶约 **8-9小时**(不含休息时间)。\n\n### 注意事项:\n1. 出发前检查车辆状况,尤其是长途驾驶的相关部件(轮胎、刹车、机油等)。\n2. 注意高速限速变化及天气情况。\n3. 可在途中适当休息,避免疲劳驾驶。\n\n祝您旅途愉快!如果需要更详细的路线或景点推荐,请告诉我!'这个案例的⼯作效果和MCP是如出⼀辙的。只不过,⾼德的MCP服务给的数据⽐较靠谱,所以⼤模型直接采纳了他的数据,⽽我们给出的意念传送的数据显然不是很靠谱,所以⼤模型虽然参考了我们给的⽅案,但是最终并没有全部采纳我们的结果。
从这⾥也能看出这种⼯具机制在处理⼀些具体问题时暴露出的⼀些核⼼问题。就是要不要调⽤⼯具,本身是⼤模型说了算。⽽最后不管⼯具给出什么样的答案,最终⼤模型回复什么内容,也还是⼤模型说了算。⾄于⼯具执⾏过程当中做了什么事情,⼤模型完全不管。
了解了这个案例后,就可以看出, MCP其实只是⼤模型⼯作机制的⼀种应⽤层的协议。
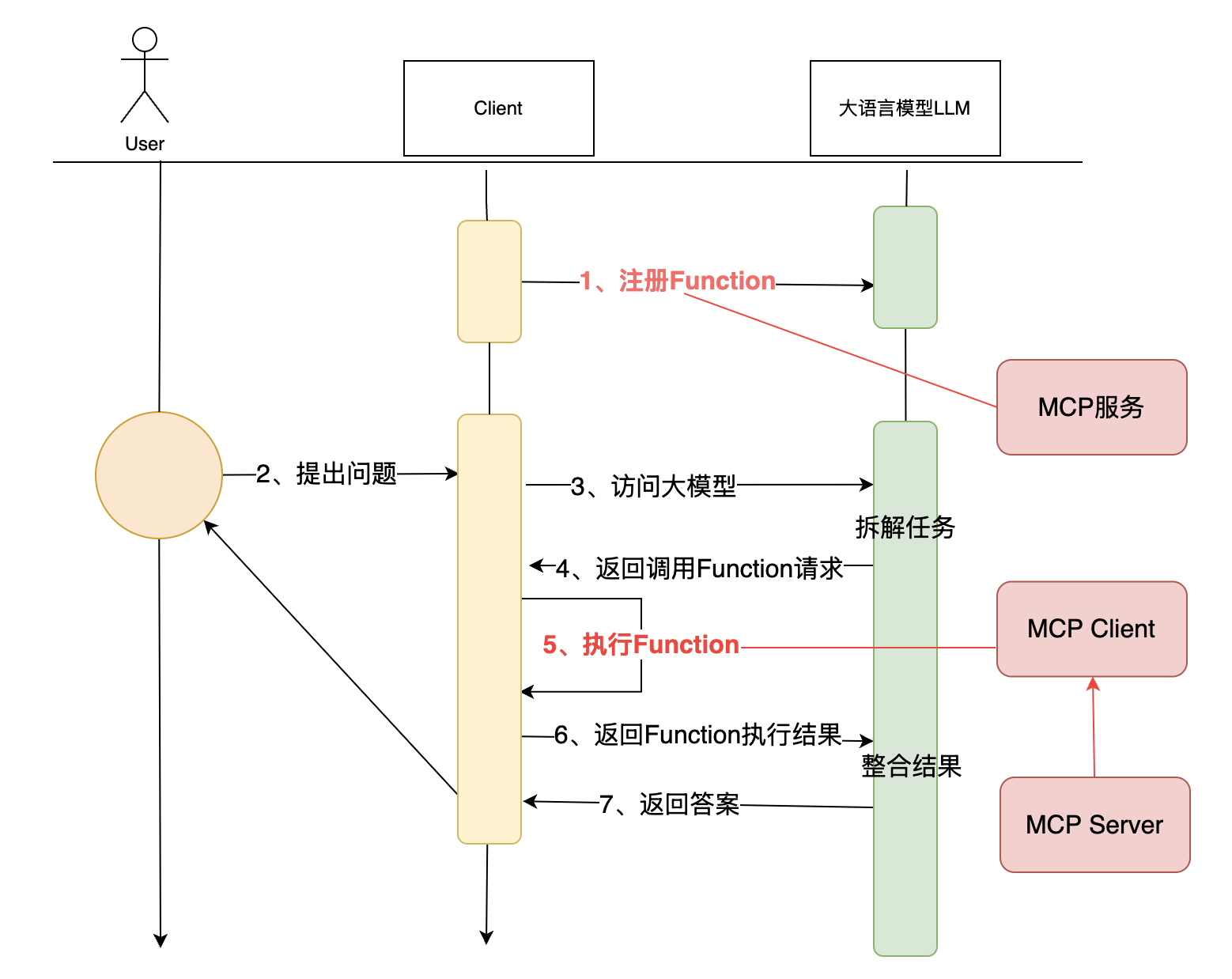
MCP协议虽然极具⼤模型的应⽤特⾊,但是本质上,MCP协议本身不包含任何具体的⼯具实现。他只是⽤协议的形式规定了应⽤程序如何向⼤模型提供函数调⽤的能⼒。
⾄于为什么MCP服务使⽤起来这么简单,其实是Cline、Lingma这样的⼯具封装了客户端的实现能⼒。这是⼯具的⼀种简化实现,和MCP协议本身是没有太⼤关系的。
这个关系就好像我们以往使⽤HTTP协议访问各种各样的⽹站⼀样的。我们这些普通⼈,可以在完全不⽤了解HTTP协议是什么东东,只要简单的使⽤浏览器就可以访问⽹站。但是,这并不意味着HTTP就是⼀个简单的协议。在HTTP协议层⾯,要考虑的问题也肯定不能只是简单的保证数据传输,还需要对⽹络传输的规范性、安全性等等各个⽅⾯做出很多的设计。
从这个功能层⾯上来说,MCP协议和HTTP协议本质上是相同的。他基于⼤模型的Function Call⼯具实现,只不过是通过协议的⽅式定义了这些⼯具要如何⼯作,这样可以极⼤的提升各种⼯具的复⽤能⼒。但是,作为⼀个协议,MCP要考虑的事情,同样不应该只是考虑这些⼯具功能如何实现,还需要在各个⽅⾯保证这些⼯具,不会出乱⼦。
但是事实是怎样的呢?接下来我们再来梳理⼀下MCP协议的两种实现⽅式 SSE和STDIO。
6.3、拆解MCP的两种实现⽅式:SSE和STDIO
还是以我们之前使⽤的⾼德地图的MCP服务为例。在⾼德地图开放平台的介绍中,提供了两种接⼊⾼德地图的MCP配置⽅式。
⼀种是我们之前使⽤过的。配置⼀个⽹站地址。这就是典型的SSE实现机制。
{
"mcpServers": {
"amap-amap-sse": {
"url": "https://mcp.amap.com/sse?key=你在⾼德官⽹上申请的key"
}
}
}另⼀种,没有使⽤过的STDIO的配置⽅式是这样的:
{
"amap-maps": {
"command": "npx",
"args": [
"-y",
"@amap/amap-maps-mcp-server"
],
"env": {
"AMAP_MAPS_API_KEY": "⾼德地图key"
}
}
}这种⽅式配置⽅式需要在本地安装Nodejs。很显然是通过在本地执⾏npx指令,执⾏了⼀个应⽤程序,从⽽获得⾼德地图的数据。
⾄于这个数据是如何获得的?是调⽤远端⾼德地图的服务获得的?还是读取本地某个神秘⽂件获取的?这就只有在⾼德地图提供的Nodejs源码@amap/amap-maps-mcp-server中才能知道了。
从这个案例中我们就能理解出SSE和STDIO到底是怎样的⼯作机制。
SSE:其实是⼀种基于HTTP协议实现的⻓连接协议,只不过SSE协议是⼀种从服务端向客户端单向推送数据的⻓连接协议。也就是⾼德地图需要提供⼀个HTTP服务,然后客户端可以和这个HTTP服务建⽴⼀个⻓连接,这样客户端就可以不断的访问⾼德地图的HTTP服务,获得⾼德地图的服务数据。这时候的⼯作机制其实和以往我们熟悉的基于HTTP的⼯作机制本质上是很像的。只是服务端的性能压⼒会⼤⼀点⽽已。
STDIO: 这种⼯作机制的本质是在客户端本地执⾏⼀个应⽤程序,然后通过应⽤程序获得对应的结果。这时候MCP的核⼼问题就出来了。MCP的服务是由MCP的服务提供者设计的,但是执⾏却是在客户端的机器执⾏。 也就是说,这给服务提供者提供了⼀种操作客户端机器的机会。这⾥⾯会带来多少安全问题?修改⼀下你本地的⽂件,或者给你植⼊⼀个病毒程序,或者。。。。。⼤家可以发挥⼀下⾃⼰的想象。
七、Agent接⼊MCP服务
LangChain中提供了⼀个新的功能模块 langchain-mcp-adapters 来⽀持MCP服务
# 安装对应依赖
!pip install langchain-mcp-adapters接下来接⼊MCP服务也相当简单,只要增加MCP的配置⽂件就⾏。
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.prebuilt import create_react_agent
from langchain_community.chat_models import ChatTongyi
# 构建阿里云百炼大模型客户端
llm = ChatTongyi(
model="qwen-plus",
api_key="key", # 从配置加载 API 密钥
)
# 配置 MCP 客户端
client = MultiServerMCPClient(
{
# 配置 amap-amap-sse
# "amap-amap-sse": {
# "url": "https://mcp.amap.com/sse?key=55ca6301504f5a08528818739a3ed492", # 使用您自己的 API 密钥
# "transport": "sse"
# },
# 配置 amap-maps,使用 npx 启动本地 MCP 服务, 这种方法不成功
"amap-maps": {
"command": "npx",
"args": [
"-y",
"@amap/amap-maps-mcp-server"
], # 使用高德地图的 MCP 服务
"env": {"AMAP_MAPS_API_KEY": "key"}, # 使用您自己的 API 密钥
"transport": "stdio"
},
}
)
# 获取工具并创建代理
tools = await client.get_tools()
agent = create_react_agent(
model=llm,
tools=tools
)
# 调用代理进行自驾路线规划
response = await agent.ainvoke(
{"messages": [{"role": "user", "content": "帮我规划一条从长沙梅溪湖到溁湾镇的自驾路线"}]}
)
# 输出代理的响应
response# 八、手写一个MCP服务
如何实现⼀个MCP服务?MCP的官⽹上提供了⼀系列的SDK来辅助实现MCP的客户端和服务端。官⽹地址: https://modelcontextprotocol.io/introduction
那么接下来的事情就简单了。我⽤python客户端来实现⼀个MCP服务看看。
8.1⼿写SSE实现
⾸先需要安装MCP依赖
!pip install mcp然后,就可以参照官⽹案例,快速实现⼀个MCP服务(在pycharm运行)
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("roymcpdemo")
@mcp.tool()
def add(a: int, b: int) -> int :
"""Add two numbers together."""
print(f"roy mcp demo called : add({a}, {b})")
return a + b
@mcp.tool()
def weather(city: str):
"""获取某个城市的天⽓
Args:
city: 具体城市
"""
return "城市" + city + ",今天天⽓不错"
@mcp.resource("greeting://{name}")
def greeting(name: str) -> str:
"""Greet a person by name."""
print(f"roy mcp demo called : greeting({name})")
return f"Hello, {name}!"
if __name__ == "__main__":
# 以sse协议暴露服务。
mcp.run(transport='sse')
# 以stdio协议暴露服务。
# mcp.run(transport='stdio')启动后可以看到:
INFO: Started server process [11240]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)然后去Lingma中配置自定义的MCP服务
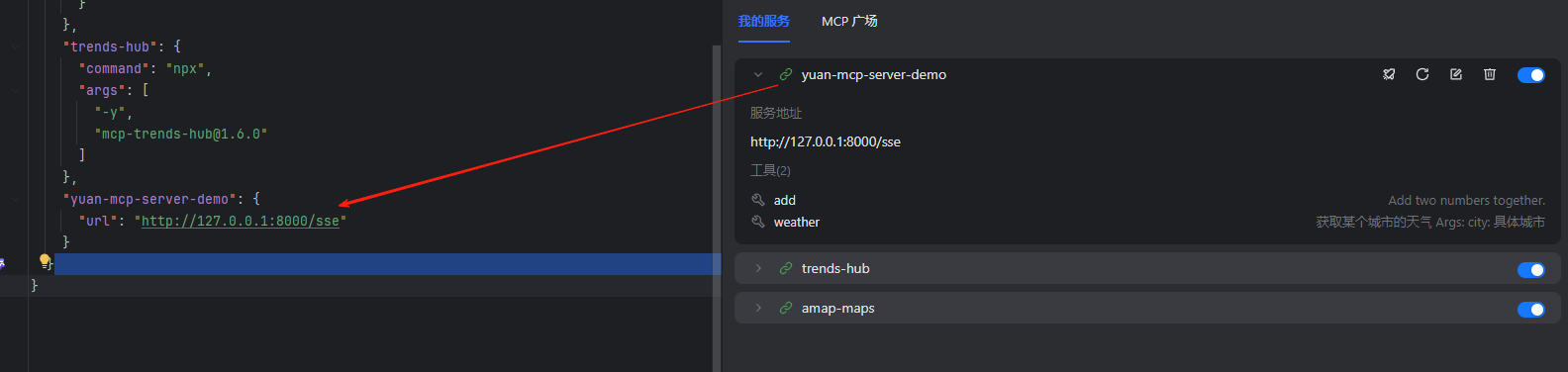
配置完成后,就可以在Lingma中看到我们声明的⼯具和资源了。
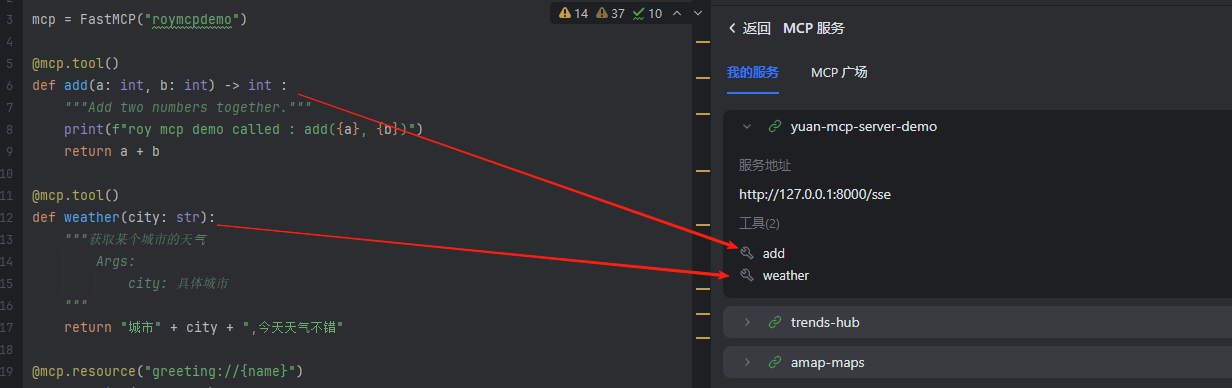
8.2 切换成STDIO实现
要切换成STDIO的协议,也很简单。对于服务端,只需要修改最后⼀⾏代码。
if __name__ == "__main__":
# 以sse协议暴露服务。
# mcp.run(transport='sse')
# 以stdio协议暴露服务。
mcp.run(transport='stdio')这时候,就需要⼀个客户端程序,来获取服务端的这些功能。整体上,也还是处理这⼏个请求。
from mcp import StdioServerParameters, stdio_client, ClientSession
import mcp.types as types
# 定义服务器参数
# 这里我们通过 StdioServerParameters 配置 MCP 服务器的启动命令和参数
server_params = StdioServerParameters(
command="python", # 要执行的命令,这里是 Python
args=["/Users/roykingw/Desktop/a_work/LangChain/LangChainAIDemo/src/mcpdemo/mcp_server.py"], # 要执行的 Python 脚本路径
env=None # 环境变量,这里设为 None,表示使用默认环境
)
# 处理消息的异步函数
# 该函数在每次收到消息时被调用,模拟一个模型的输出
async def handle_sampling_message(message: types.CreateMessageRequestParams) -> types.CreateMessageResult:
print(f"sampling message: {message}") # 打印接收到的消息内容
return types.CreateMessageResult(
role="assistant", # 设置返回消息的角色为 "assistant"
content=types.TextContent(
type="text", # 设置内容类型为文本
text="Hello, world! from model" # 模拟返回的消息内容
),
model="qwen-plus", # 设置使用的模型
stopReason="endTurn" # 设置结束原因为 "endTurn",表示对话结束
)
# 运行主逻辑的异步函数
# 在该函数中,我们通过 MCP 客户端与服务器交互,获取提示、工具和资源
async def run():
# 使用 stdio_client 创建与服务器的连接
async with stdio_client(server_params) as (read, write):
# 创建客户端会话并与服务器进行交互
async with ClientSession(read, write, sampling_callback=handle_sampling_message) as session:
await session.initialize() # 初始化会话
# 获取并打印可用的提示列表
prompts = await session.list_prompts()
print(f"prompts: {prompts}")
# 获取并打印可用的工具列表
tools = await session.list_tools()
print(f"tools: {tools}")
# 获取并打印可用的资源列表
resources = await session.list_resources()
print(f"resources: {resources}")
# 调用 weather 工具,传递城市参数 "北京",并打印返回的结果
result = await session.call_tool("weather", {"city": "北京"})
print(f"result: {result}")
# 主程序入口
# 该部分代码会在程序启动时执行,确保异步任务能被正确运行
if __name__ == "__main__":
import asyncio
asyncio.run(run()) # 使用 asyncio 运行异步函数 run()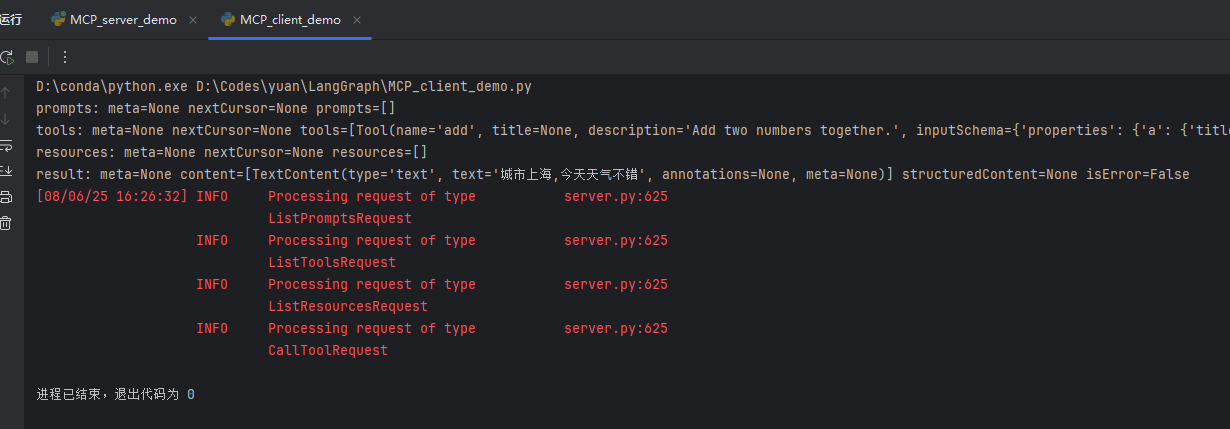
接下来,也可以⽤同样的⽅式尝试在LangGraph中接⼊服务。
当然,由于需要依赖服务端的代码实现,所以不能简单的配置⼀个python指令执⾏。需要打包成nodejs依赖启动。后续就不再做介绍了。
8.3 总结
通过深度演示MCP服务的客户端和服务端的交互过程,让⼤家对MCP服务有了初步的了解。在深度使⽤更多的MCP服务的同时,合理的看待MCP的安全问题。虽然MCP最⼤的意义在于简化客户端的调⽤过程,让我们以极⼩的代价快速接⼊更多的外部服务,但是并不代表MCP服务就是安全的。
九、深度理解LangGraph核⼼-Graph
在了解了LangGraph中如何构建Agent智能体之后,接下来就要进⼊LangGraph的重头戏,Graph了。Graph是LangGraph的核⼼,它以有向⽆环图的⽅式来串联多个Agent,构建更复杂的Agent⼤模型应⽤,形成更复杂的⼯作流。并且提供了很多产品级的特性,保证这些应⽤可以更稳定⾼效的执⾏。
9.1 理解什么是Graph图
Graph是LangGraph的基本构建模块,它是⼀个有向⽆环图(DAG),⽤于描述任务之间的依赖关系。主要包含三个基本的元素:
State: 在整个应⽤当中共享的⼀种数据结构。
Node : ⼀个处理数据的节点。LangGraph中通常是⼀个Python的函数,以State为输⼊,经过⼀些操作后,返回更新后的State。
Edge : 表示Node之前的依赖关系。LangGraph中通常也是⼀个Python函数,根据当前State来决定接下来执⾏哪个Node。
接下来⽤⼀个最简单的案例,来看⼀下Graph的基本⽤法。
#安装依赖
!pip install -U langgraphfrom typing import TypedDict
from langgraph.constants import END, START # 导入状态图的常量 END 和 START
from langgraph.graph import StateGraph # 导入状态图构建器
# 定义输入状态的类型
class InputState(TypedDict):
user_input: str # 用户输入的文本
# 定义输出状态的类型
class OutputState(TypedDict):
graph_output: str # 图的输出结果
# 定义整体状态类型,它包含了输入、图状态和输出
class OverallState(TypedDict):
foo: str # 从节点 1 传递来的信息
user_input: str # 用户输入的文本
graph_output: str # 图的最终输出
# 定义私有状态类型
class PrivateState(TypedDict):
bar: str # 从节点 2 传递来的信息
# 节点 1:根据输入状态生成整体状态
def node_1(state: InputState) -> OverallState:
# 从输入状态读取用户输入并更新整体状态的 "foo" 字段
return {"foo": state["user_input"] + ">帅哥"}
# 节点 2:根据整体状态生成私有状态
def node_2(state: OverallState) -> PrivateState:
# 从整体状态读取 "foo" 字段并更新私有状态的 "bar" 字段
return {"bar": state["foo"] + ">⾮常"}
# 节点 3:根据私有状态生成输出状态
def node_3(state: PrivateState) -> OutputState:
# 从私有状态读取 "bar" 字段并生成输出状态
return {"graph_output": state["bar"] + ">靠谱"}
# 创建状态图构建器,指定整体状态为输入和输出
builder = StateGraph(OverallState, input=InputState, output=OutputState)
# 添加节点到状态图中
builder.add_node("node_1", node_1) # 添加节点 1
builder.add_node("node_2", node_2) # 添加节点 2
builder.add_node("node_3", node_3) # 添加节点 3
# 添加边(表示节点间的关系和流程)
builder.add_edge(START, "node_1") # 从起始节点连接到节点 1
builder.add_edge("node_1", "node_2") # 从节点 1 连接到节点 2
builder.add_edge("node_2", "node_3") # 从节点 2 连接到节点 3
builder.add_edge("node_3", END) # 从节点 3 连接到结束节点
# 编译图,准备执行
graph = builder.compile()
# 调用图,传递初始输入
result = graph.invoke({"user_input": "元仔"}) # 输入 "图灵" 来启动图的执行
# 输出最终结果
print(result)这个案例当中,请求的参数从固定的START传⼊,依次经过三个节点处理,每个节点的处理结果都会被保存到不同的state当中,最后进⼊到END节点结束。
如果你觉得这个流程不够明显,还可以直接⽤真正的图来看看请求是如何处理的。
from IPython.display import Image, display
# draw_mermaid⽅法可以打印出Graph的mermaid代码。
display(Image(graph.get_graph().draw_mermaid_png()))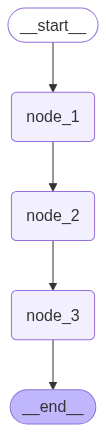
可以看到,⼀个Graph中,可以通过对Node和Edge的灵活组合,形成各种复杂的流程。接下来,我就是要接⼊Agent,来完成各种复杂的任务。
在构建复杂任务之前,我们先来仔细看看Graph中的这三个主要组件。
9.2 主要组件
9.2.1 State 状态
State是所有节点共享的状态,它是⼀个字典,包含了所有节点的状态。有⼏个需要注意的地⽅:
State形式上,可以是TypedDict字典,也可以是Pydantic中的⼀个BaseModel。例如
from pydantic import BaseModel
# The overall state of the graph (this is the public state shared across nodes)
class OverallState(BaseModel):
a: str这两种实现,本质上没有太多的区别。
State中定义的属性,通常不需要指定默认值。如果需要默认值,可以通过在START节点后,定义⼀个node来指定默认值。
def node(state: OverallState):
return {"a": "goodbye"}State中的属性,除了可以修改值之外,也可以定义⼀些操作。来指定如何更新State中的值。 例如
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
list_field: Annotated[list[int],add]
extra_field: int此时,如果有⼀个node,返回了State中更新的值, 那么messages和list_field的值就会添加到原有的旧集合中,
⽽extra_field的值则会被替换。
from langchain_core.messages import AnyMessage, AIMessage
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
from typing import Annotated, TypedDict
from operator import add
# 定义 State 类型,表示图的状态结构
# State 包含以下字段:
# 1. messages: 存储消息的列表,使用 `add_messages` 函数作为标注
# 2. list_field: 存储整数的列表,使用 `add` 函数作为标注
# 3. extra_field: 存储一个整数
class State(TypedDict):
messages: Annotated[list[AnyMessage], add_messages] # 消息列表
list_field: Annotated[list[int], add] # 整数列表
extra_field: int # 额外的整数字段
# 节点 1:处理状态并生成新的消息,更新状态
def node1(state: State):
# 创建一个新的 AIMessage
new_message = AIMessage("Hello \n--by AI!")
# 返回新的状态,包含生成的消息,整数列表,以及额外的字段
return {
"messages": [new_message],
"list_field": [10], # 更新整数列表
"extra_field": 10 # 更新额外字段
}
# 节点 2:处理状态并生成新的消息,更新状态
def node2(state: State):
# 创建一个新的 AIMessage
new_message = AIMessage("LangGraph!")
# 返回新的状态,包含生成的消息,整数列表,以及额外的字段
return {
"messages": [new_message],
"list_field": [20], # 更新整数列表
"extra_field": 20 # 更新额外字段
}
# 创建状态图
graph = (
StateGraph(State) # 创建一个图,状态类型为 State
.add_node("node1", node1) # 添加节点 1
.add_node("node2", node2) # 添加节点 2
.set_entry_point("node1") # 设置入口节点为 node1
.add_edge("node1", "node2") # 添加节点之间的边,表示执行顺序
.compile() # 编译图,准备执行
)
# 定义输入消息
input_message = {"role": "user", "content": "Hi"}
# 调用图,传入输入消息和初始的整数列表
result = graph.invoke({"messages": [input_message], "list_field": [1, 2, 3]})
# 输出结果
print(result)
# for message in result["messages"]:
# message.pretty_print()
# print(result["extra_field"])在LangGraph的应⽤当中,State通常都会要保存聊天消息。为此,LangGraph中还提供了⼀个langgraph.graph.MessagesState,可以⽤来快速保存消息。
他的声明⽅式就是这样的:
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]然后,对于Messages,也可以⽤序列化的⽅式来声明,例如下⾯两种⽅式都是可以的
{"messages": [HumanMessage(content="message")]}
{"messages": [{"type": "user", "content": "message"}]}9.2.2 Node 节点
Node是图中的⼀个处理数据的节点。也有以下⼏个需要注意的地⽅:
在LangGraph中,Node通常是⼀个Python的函数,它接受⼀个State对象作为输⼊,返回⼀个State对象作为输出。
每个Node都有⼀个唯⼀的名称,通常是⼀个字符串。如果没有提供名称,LangGraph会⾃动⽣成⼀个和函数名⼀样的名称。
在具体实现时,通常包含两个具体的参数,第⼀个是State,这个是必选的。第⼆个是⼀个可选的配置项config。这⾥⾯包含了⼀些节点运⾏的配置参数。
LangGraph对每个Node提供了缓存机制。只要Node的传⼊参数相同,LangGraph就会优先从缓存当中获取Node的执⾏结果。从⽽提升Node的运⾏速度。
import time
from typing import TypedDict
from langchain_core.runnables import RunnableConfig
from langgraph.constants import START, END # 导入图的开始和结束常量
from langgraph.graph import StateGraph # 导入状态图构建器
from langgraph.types import CachePolicy # 导入缓存策略
from langgraph.cache.memory import InMemoryCache # 从 langgraph 的内存缓存中导入 InMemoryCache
# 配置状态类型
# State 表示图的状态结构,包含用户输入的数字(number)和用户 ID(user_id)
class State(TypedDict):
number: int # 用户输入的数字
user_id: str # 用户 ID
# 配置节点的配置信息(可配置的字段)
# ConfigSchema 表示每个节点配置的模式,包含用户 ID
class ConfigSchema(TypedDict):
user_id: str # 用户 ID
# 节点 1:根据状态和配置计算并返回新的状态
def node_1(state: State, config: RunnableConfig):
# 模拟延迟操作
time.sleep(3)
# 从配置中读取用户 ID
user_id = config["configurable"]["user_id"]
# 返回更新后的状态
return {"number": state["number"] + 1, "user_id": user_id}
# 创建状态图
builder = StateGraph(State, context_schema=ConfigSchema)
# 添加节点到状态图
# 设置节点 1 的缓存策略,TTL 为 5 秒,即缓存 5 秒
builder.add_node("node1", node_1, cache_policy=CachePolicy(ttl=5))
# 添加节点之间的边,表示从 START 到 "node1",然后到 END
builder.add_edge(START, "node1")
builder.add_edge("node1", END)
# 编译图,使用内存缓存
graph = builder.compile(cache=InMemoryCache())
# 调用图,传递输入并输出结果
# 这里我们传入了 "number": 5 和 "configurable" 中的 "user_id": "123"
print(graph.invoke({"number": 5}, config={"configurable": {"user_id": "123"}}, stream_mode='updates'))
# 输出: [{'node1': {'number': 6, 'user_id': '123'}}]
# 调用图,传递不同的配置(不同的 user_id)
# 因为缓存是基于相同的 "number" 和 "user_id" 配置来缓存的,所以新配置会走缓存
print(graph.invoke({"number": 5}, config={"configurable": {"user_id": "456"}}, stream_mode='updates'))
# 输出: [{'node1': {'number': 6, 'user_id': '123'}, '__metadata__': {'cached': True}}]对于Node,LangGraph除了提供缓存机制,还提供了重试机制。
可以针对单个节点指定,例如:
from langgraph.types import RetryPolicy
builder.add_node("node1", node_1,retry=RetryPolicy(max_attempts=4))另外,也可以针对某⼀次任务调⽤指定,例如
print(graph.invoke(xxxxx, config={"recursion_limit":25})) # 递归深度为259.2.3 Edge 边
在Graph图中,通过Edge(边)把Node(节点)连接起来,从⽽决定State应该如何在Graph中传递。LangGraph中也提供了⾮常灵活的构建⽅式。
- 普通Edge和EntryPoint
Edge通常是⽤来把两个Node连接起来,形成逻辑处理路线。例如 graph.add_edge("node_1","node_2") 。LangGraph中提供了两个默认的Node, START和END,⽤来作为Graph的⼊⼝和出⼝。同时,也可以⾃⾏指定EntryPoint。例如
builder = StateGraph(State)
builder.set_entry_point("node1")
builder.set_finish_point("node2")条件Edge和EntryPoint
我们也可以添加带有条件判断的Edge和EntryPoint,⽤来动态构建更复杂的⼯作流程。具体实现时,可以指定⼀个函数,函数的返回值就可以是下⼀个Node的名称。
from typing import TypedDict
from langchain_core.runnables import RunnableConfig
from langgraph.constants import START, END # 导入图的起始和结束常量
from langgraph.graph import StateGraph # 导入状态图构建器
# 配置状态类型
# State 类型定义了图的状态结构,包含一个整数值 number
class State(TypedDict):
number: int # 状态中的数字字段
# 定义节点 1:接收当前状态,返回更新后的状态
def node_1(state: State, config: RunnableConfig):
# 将数字加 1,并返回新的状态
return {"number": state["number"] + 1}
# 创建状态图,图的状态类型为 State
builder = StateGraph(State)
# 添加节点 "node1",该节点执行 `node_1` 函数
builder.add_node("node1", node_1)
# 定义一个路由函数,根据当前状态决定要跳转到哪个节点
# 如果 number > 5,则跳转到 "node1";否则,跳转到结束节点(END)
def routing_func(state: State) -> str:
if state["number"] > 5:
return "node1" # 跳转到 "node1"
else:
return END # 跳转到结束节点
# 添加从 "node1" 到结束节点的边
builder.add_edge("node1", END)
# 添加条件边,根据路由函数的返回值决定跳转路径
builder.add_conditional_edges(START, routing_func)
# 编译图,准备执行
graph = builder.compile()
# 执行图,传入初始状态 {"number": 7}
print(graph.invoke({"number": 7}))# 补充看⼀下Graph的结构
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
另外,如果不想在路由函数中写⼊过多具体的节点名称,也可以在函数中返回⼀个⾃定义的结果,然后将这个结果解析到某⼀个具体的Node上。例如
# 定义路由函数,返回 True 或 False 来选择不同的路径
def routing_func(state: State) -> bool:
if state["number"] > 5:
return True # 如果 number 大于 5,返回 True,跳转到 "node_a"
else:
return False # 否则,返回 False,跳转到 "node_b"Send动态路由
在条件边中,如果希望⼀个Node后同时路由到多个Node,就可以返回Send动态路由的⽅式实现。
Send对象可传⼊两个参数,第⼀个是下⼀个Node的名称,第⼆个是Node的输⼊。
from operator import add
from typing import TypedDict, Annotated
from langgraph.constants import START, END # 导入图的起始和结束常量
from langgraph.graph import StateGraph # 导入状态图构建器
from langgraph.types import Send # 导入 Send 类型,用于发送消息
# 配置状态类型
class State(TypedDict):
messages: Annotated[list[str], add] # 消息列表,使用 add 函数进行标注
# 配置私有状态类型
class PrivateState(TypedDict):
msg: str # 私有状态的消息
# 定义节点 1:接收 PrivateState,生成新的消息并返回新的状态
def node_1(state: PrivateState) -> State:
# 在消息末尾添加 "!" 并返回新的消息
res = state["msg"] + "!"
return {"messages": [res]} # 返回包含新的消息的状态
# 创建状态图,图的状态类型为 State
builder = StateGraph(State)
# 向图中添加节点 1
# 设置节点缓存时间为 5 秒
builder.add_node("node1", node_1)
# 定义路由函数:遍历消息列表,将每个消息通过 Send 发送到 "node1"
def routing_func(state: State):
result = []
# 遍历状态中的每个消息
for message in state["messages"]:
# 将每个消息通过 Send 发送到 "node1"
result.append(Send("node1", {"msg": message}))
return result # 返回发送的结果列表
# 通过路由函数,将消息列表中的每个消息传入 "node1" 进行处理
builder.add_conditional_edges(START, routing_func, ["node1"])
# 添加从 "node1" 到结束节点的边
builder.add_edge("node1", END)
# 编译图
graph = builder.compile()
# 执行图,传入初始状态
print(graph.invoke({"messages": ["hello", "world", "hello", "graph"]}))# 补充看⼀下Graph的结构
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))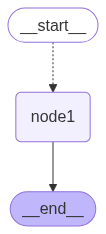
Command命令
通常,Graph中⼀个典型的业务步骤是State进⼊⼀个Node处理。在Node中先更新State状态,然后再通过Edges传递给下⼀个Node。如果希望将这两个步骤合并为⼀个命令,那么还可以使⽤Command命令。
from operator import add
from typing import TypedDict, Annotated
from langgraph.constants import START, END # 导入图的起始和结束常量
from langgraph.graph import StateGraph # 导入状态图构建器
from langgraph.types import Command # 导入 Command 类型,用于控制图的流程和状态更新
# 配置状态类型
# State 定义了图的状态结构,包含一个字符串列表 messages
class State(TypedDict):
messages: Annotated[list[str], add] # 消息列表,使用 add 函数进行标注
# 定义节点 1:根据当前状态更新消息并返回新的状态
def node_1(state: State):
# 创建一个新的消息列表,每个消息末尾加上 "!"
new_message = []
for message in state["messages"]:
new_message.append(message + "!")
# 返回 Command 对象,表示状态更新并跳转到结束节点
return Command(
goto=END, # 指定下一个节点为 END
update={"messages": new_message} # 更新消息列表
)
# 创建状态图,状态类型为 State
builder = StateGraph(State)
# 添加节点 1,并设置它执行 node_1
builder.add_node("node1", node_1)
# 添加从 START 到 "node1" 的边
builder.add_edge(START, "node1")
# 编译图,生成可执行的图对象
graph = builder.compile()
# 执行图,传入初始状态
print(graph.invoke({"messages": ["hello", "world", "hello", "graph"]}))十、子图
在LangGraph中,⼀个Graph除了可以单独使⽤,还可以作为⼀个Node,嵌⼊到另⼀个Graph中。这种⽤法就称为⼦图。通过⼦图,我们可以更好的重⽤Graph,构建更复杂的⼯作流。尤其在构建多Agent时,⾮常有⽤。在⼤型项⽬中,通常都是由⼀个团队专⻔开发Agent,再通过其他团队来完整Agent整合。
使用子图时,基本和使⽤Node没有太多的区别。
唯⼀需要注意的是,当触发了SubGraph代表的Node后,实际上是相当于重新调⽤了⼀次subgraph.invoke(state)⽅法。
from operator import add
from typing import TypedDict, Annotated
from langgraph.constants import END # 导入图的结束常量
from langgraph.graph import StateGraph, MessagesState, START # 导入图构建器和状态类型
# 配置状态类型
# State 定义了图的状态结构,包含一个消息列表 messages
class State(TypedDict):
messages: Annotated[list[str], add] # 消息列表,使用 add 函数进行标注
# 定义子图的节点 sub_node_1
# 子图节点将返回一个包含 "response from subgraph" 的消息列表
def sub_node_1(state: State) -> MessagesState:
return {"messages": ["response from subgraph"]}
# 子图构建器
subgraph_builder = StateGraph(State)
subgraph_builder.add_node("sub_node_1", sub_node_1) # 向子图中添加节点 sub_node_1
subgraph_builder.add_edge(START, "sub_node_1") # 从 START 到 sub_node_1
subgraph_builder.add_edge("sub_node_1", END) # 从 sub_node_1 到 END
subgraph = subgraph_builder.compile() # 编译子图
# 主图构建器
builder = StateGraph(State)
builder.add_node("subgraph_node", subgraph) # 向主图中添加子图节点
builder.add_edge(START, "subgraph_node") # 从 START 到 subgraph_node
builder.add_edge("subgraph_node", END) # 从 subgraph_node 到 END
# 编译主图
graph = builder.compile()
# 执行主图,传入初始状态
print(graph.invoke({"messages": ["hello subgraph"]}))十一、图的Stream⽀持
和调⽤⼤模型相似,Graph除了可以通过invoke⽅法进⾏直接调⽤外,也⽀持通过stream()⽅法进⾏流式调⽤。不过⼤模型的流式调⽤是依次返回⼤模型响应的Token。⽽Graph的流式输出则是依次返回State的数据处理步骤。graph提供了stream()⽅法进⾏同步的流式调⽤,也提供了astream()⽅法进⾏异步的流式调⽤。
for chunk in graph.stream({"messages": ["hello subgraph"]},stream_mode="debug"):
print(chunk)
# {'subgraph_node': {'messages': ['hello subgraph', 'response from subgraph']}}LangGraph⽀持⼏种不同的stream mode:
values:在图的每⼀步之后流式传输状态的完整值
updates:在图的每⼀步之后,将更新内容流式传输到状态。如果在同⼀步骤中进⾏了多次更新(例如,运⾏了多个节点),这些更新将分别进⾏流式传输。
custom:从图节点内部流式传输⾃定义数据。通常⽤于调试。
messages:从任何调⽤⼤语⾔模型(LLM)的图节点中,流式传输⼆元组(LLM的Token ,元数据)
debug:在图的执⾏过程中尽可能多地传输信息。⽤得⽐较少。values、updates、debug输出模式,使⽤之前案例验证,就能很快感受到其中的区别。
messages输出模式,由于在之前案例中并没有调⽤⼤模型,所以不会有输出结果。
⽽custom输出模式,可以⾃定义输出内容。在Node节点内或者Tools⼯具内,通过get_stream_writer()⽅法获取⼀个StreamWriter对象,然后使⽤write()⽅法将⾃定义数据写⼊流中。
from typing import TypedDict
from langgraph.config import get_stream_writer # 导入流写入器
from langgraph.graph import StateGraph, START # 导入状态图构建器和常量
# 定义状态类型 State,包含 query 和 answer 字段
class State(TypedDict):
query: str # 用户的查询输入
answer: str # 节点返回的答案
# 定义节点的逻辑
def node(state: State):
# 获取流写入器
writer = get_stream_writer()
# 写入自定义的键值对信息,流式传输自定义数据
writer({"自定义key": "在节点内返回自定义信息"}) # 流写入自定义的信息
# 返回更新后的状态,包含计算的答案
return {"answer": "some data"}
# 构建状态图
graph = (
StateGraph(State) # 创建一个状态图,状态类型为 State
.add_node(node) # 添加节点,节点执行 node 函数
.add_edge(START, "node") # 从 START 节点到 "node" 节点
.compile() # 编译图
)
# 设置输入数据
inputs = {"query": "example"} # 初始查询数据
# 流式传输数据
# 使用自定义的流模式,获取每个数据块
for chunk in graph.stream(inputs, stream_mode="custom"):
print(chunk) # 打印每个数据块最后,在langChain中,构建LLM对象时,⼤都⽀持desable_streaming属性,禁⽌流式输出。例如:
llm = ChatOpenAI(model="", disable_streaming=True)
llm = ChatOpenAI(model="", disable_streaming=True)总结
在这⼀章节,我详细演练了LangGraph中的Graph构建以及⼯作⽅式。可以看到,Graph图的构建⾮常灵活,我可以⾃由地构建各种复杂的图结构。即使是没有与⼤模型交互的图,也可以通过LangGraph来构建。这对于处理传统任务也是⾮常有⽤的。
当然,LangGraph中的图,还是要有⼤模型的加持,才能更好的体现他的强⼤之处。下⼀章节我就着重去演练⼤模型加持下的LangGraph。
在这⾥,不妨回顾⼀下LangChain中的Chain是如何构建的,并与Graph做⼀下对⽐。可以看到,这两个框架都是着眼于将多个独⽴的功能模块组合进⾏调度、组合,形成复杂的智能体。只不过,LangChain使⽤的是Chain的⽅式,⽽LangGraph是使⽤Graph的⽅式。或许这样能够更好的体会到,为什么LangGraph是LangChain的⼀个⼦项⽬,⽽不是⼀个独⽴的框架了。