若依学习🍃
听说若依挺方便的啊,那我也来试试看
一、环境配置
直接在docker中配置环境,比较方便:
ruoyi-docker-compose.yml:
version: "3.8"
services:
mysql:
image: mysql:8.0.36
container_name: ruoyi-mysql
restart: always
environment:
# root 用户密码改为 root
MYSQL_ROOT_PASSWORD: root
# 自动创建数据库 ry
MYSQL_DATABASE: ry
ports:
- "3306:3306"
volumes:
# 数据持久化
- ./docker/mysql/data:/var/lib/mysql
# 初始化脚本(首次启动时执行)
- ./docker/mysql/init:/docker-entrypoint-initdb.d
command:
--default-authentication-plugin=mysql_native_password
redis:
image: redis:7.2
container_name: ruoyi-redis
restart: always
ports:
- "6379:6379"
volumes:
- ./docker/redis/data:/data
networks:
default:
name: ruoyi-net
配置好是这样的:
然后拉取文件:https://gitee.com/y_project/RuoYi-Vue/tree/springboot3
拉取好后记得配置数据库,数据库文件在sql文件夹下
配置数据库之后还需要配置好yaml文件,路径是:ruoyi-admin/src/main/resources/application-druid.yml
前端的环境配置我是直接npm install...
之后前后端分别启动起来就好了
直接访问http://localhost就可以看到登录页: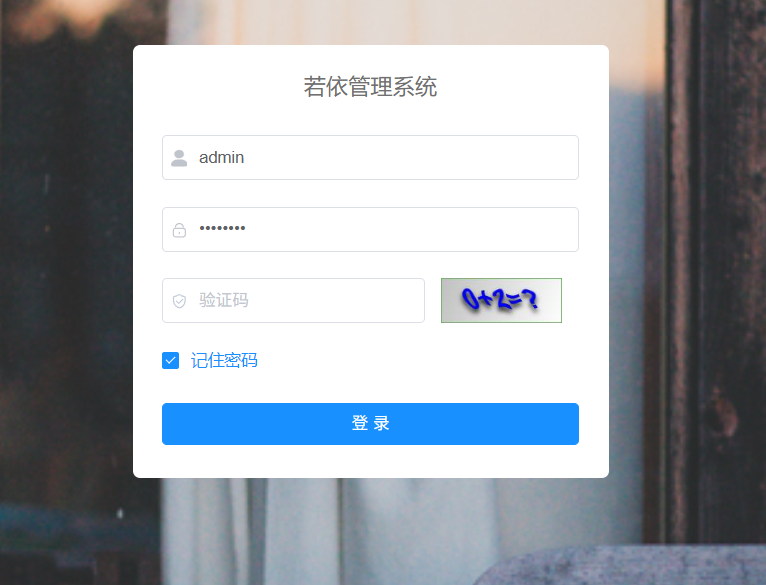
这样前期准备就算完成了。
二、学习源码--验证码(前端)
验证码这块我一直没学会,现在研究看看:
首先查看前端的ruoyi-ui/src/views/login.vue,可以看到验证码的前端实现:
getCode() {
getCodeImg().then(res => {
// 根据后端返回的 captchaEnabled,决定是否启用验证码。
this.captchaEnabled = res.captchaEnabled === undefined ? true : res.captchaEnabled
if (this.captchaEnabled) {
// 如果启用,则将后端返回的 Base64 编码的图片拼成 Data URL 赋给 codeUrl,用于 <img> 标签展示验证码。
this.codeUrl = "data:image/gif;base64," + res.img
// 同时将后端生成的 uuid 写入 loginForm.uuid,用于后续登录请求时校验验证码。
this.loginForm.uuid = res.uuid
}
})
},因为代码经过了多层嵌套和封装,所以我点进getCodeImg()方法对应的ruoyi-ui/src/api/login.js文件查看:
/**
* 获取验证码图像
* 1. 向后端发送 GET 请求,获取验证码图片及相关配置(是否启用、Base64 图片、UUID)
* 2. 因在登录前调用,此接口无需携带用户 Token
* 3. 设置超时时间,防止请求长时间挂起
*/
export function getCodeImg() {
return request({
// 接口路径:后端提供的验证码生成地址
url: '/captchaImage',
// HTTP 方法:GET 用于获取资源
method: 'get',
// 自定义请求头,用于拦截器判断是否注入 Token
headers: {
// 标记本次请求无需在请求头中携带 Authorization 或其他登录凭证
isToken: false
},
// 请求超时时间(毫秒):20 秒后若无响应则中断并抛出超时错误
timeout: 20000
})
}可以看到,代码又封装了一个request,那我接着往下看ruoyi-ui/src/utils/request.js:
...省略...
// 创建axios实例
const service = axios.create({
// axios中请求配置有baseURL选项,表示请求URL公共部分,
// 所有通过该实例发起的相对请求(如 service.get('/xxx'))
// 会自动拼接成 process.env.VUE_APP_BASE_API + '/xxx'。
baseURL: process.env.VUE_APP_BASE_API,
// 超时
timeout: 10000
})
...省略...可以看到在这里调用了axios,env.VUE_APP_BASE_API对应的是这三个文件: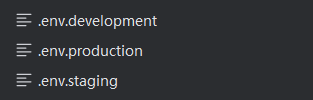
点进第一个,可以看到:
# 页面标题
VUE_APP_TITLE = 若依管理系统
# 开发环境配置
ENV = 'development'
# 若依管理系统/开发环境
VUE_APP_BASE_API = '/dev-api'
# 路由懒加载
VUE_CLI_BABEL_TRANSPILE_MODULES = true通过这种方式定义了统一的访问api: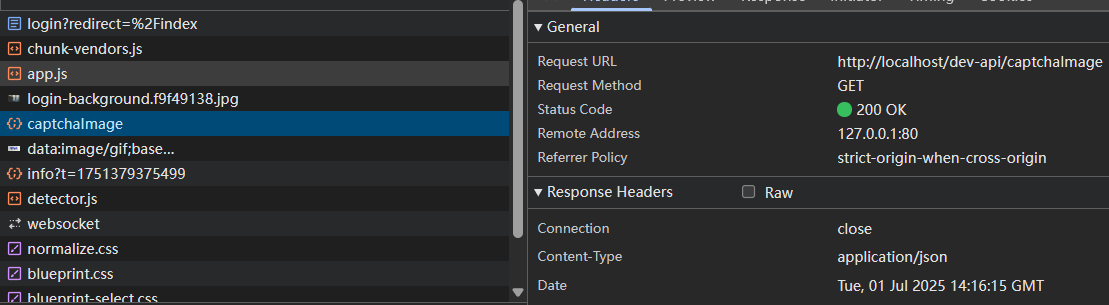
所以我们就知道了前端生成验证码的流程,然而,验证码是前端向后端发送请求后得到的,那么就涉及到了跨域问题,此时我们并没有配置nginx,那么若依是怎么做反向代理的呢?
这会我们就可以去看ruoyi-ui/vue.config.js中的proxy:
// 通过 webpack-dev-server 在本地启动一个可热重载的服务,方便调试。
devServer: {
// 监听所有网卡的地址,包括本机 localhost、局域网 IP,方便在不同设备(手机/平板)调试。
host: '0.0.0.0',
port: port,
open: true,
proxy: {
// detail: https://cli.vuejs.org/config/#devserver-proxy
[process.env.VUE_APP_BASE_API]: {
// webpack-dev-server 内置的 http-proxy-middleware,
// 会拦截匹配到的请求并转发到 target ('http://localhost:8080')。
target: baseUrl,
// changeOrigin: true 会修改请求头中的 Host 字段为目标地址,避免目标服务器拒绝服务。
changeOrigin: true,
// pathRewrite 用于重写 URL 路径,将前缀去除后再转发。
// 如:前端请求 /dev-api/captchaImage -> 代理后转到 http://localhost:8080/captchaImage
pathRewrite: {
['^' + process.env.VUE_APP_BASE_API]: ''
}
},
// 二、针对 springdoc(OpenAPI 文档)的代理
// 匹配 /v3/api-docs/... 路径,方便在前端查看 Swagger 文档
'^/v3/api-docs/(.*)': {
target: baseUrl,
changeOrigin: true
}
},
disableHostCheck: true
},明白了前端流程之后,我们就可以去看看后端是怎么实现的了。
三、学习源码--验证码(后端)
通过万能的idea的全局搜索,搜索captchaImage,我就能找到实现验证码的controller:CaptchaController。
查看代码的getCode方法,我们可以看到一个AjaxResult 类,这个类是用来做Ajax的后端向前端统一返回结果的包装类,里面提供了多种静态工厂方法AjaxResult.success()、AjaxResult.success(data)、AjaxResult.error(msg)、AjaxResult.warn(msg) 等,代码后面定义的put方法使我们能够进行链式调用:
/**
* 方便链式调用
*
* @param key 键
* @param value 值
* @return 数据对象
*/
@Override
public AjaxResult put(String key, Object value)
{
super.put(key, value);
return this;
}AjaxResult 是继承自 HashMap<String, Object> 的类,super.put(key, value) 就是调用了 HashMap 的 put 方法,把键值对放进去。return this; 表示返回当前对象实例(AjaxResult 对象本身),实现链式调用的基础。
链式调用就可以像这样:
result.put("name", "张三").put("age", 18).put("sex", "男");方法返回自己本身,就可以连着点点点。而为什么这么做呢,因为给前端返回数据时可能需要这样返回:
{
"code": 200,
"msg": "操作成功",
"data": {
"name": "张三",
"age": 18
}
}然后我就可以直接:
return AjaxResult.success()
.put("name", "张三")
.put("age", 18);达到我想要的效果,就比每次 new Map 再 set、再 return 简洁多了。
然后我们回到验证码方法:
生成uuid,在前面加上redis key:captcha_codes: 得到每个用户对应的verifyKey。
接着生成math验证码:
if ("math".equals(captchaType))
{
String capText = captchaProducerMath.createText(); // e.g. "3+5@8"
capStr = capText.substring(0, capText.lastIndexOf("@")); // "3+5"
code = capText.substring(capText.lastIndexOf("@") + 1); // "8"
image = captchaProducerMath.createImage(capStr);
}可以看到调用的createText()方法创建了一个数学运算,问题和结果使用@进行分割,这个方法是 import com.google.code.kaptcha.Producer;带有的。
生成字符验证码也是同理,略。
生成好验证码之后就存入redis缓存中去,把验证码答案 code ,key 为 verifyKey,并设置有效期(默认2min):
redisCache.setCacheObject(verifyKey, code, Constants.CAPTCHA_EXPIRATION, TimeUnit.MINUTES);然后就可以把生成的图片写入内存流,编码为 Base64 字符串。其中FastByteArrayOutputStream是 Spring 工具包提供的,比ByteArrayOutputStream的初始容量更大(256 bytes),动态扩容逻辑更激进(当空间不足时,buf.length << 1(即翻倍)扩容),内存复制更高效。
这样,验证码的前后端的业务流程就看完了。
四、学习源码--登录(前端)
查看login.vue的 handleLogin() 方法:
if (this.loginForm.rememberMe) {
Cookies.set("username", this.loginForm.username, { expires: 30 })
Cookies.set("password", encrypt(this.loginForm.password), { expires: 30 })
Cookies.set('rememberMe', this.loginForm.rememberMe, { expires: 30 })
}这一部分是当勾选了记住用户名密码时把它们存到Cookies中去。
然后是:
this.$store.dispatch("Login", this.loginForm)这是Vuex里共享的全局方法,Login Action,点进去可以看到封装好的内容ruoyi-ui/src/store/modules/user.js:
actions: {
// 登录
Login({ commit }, userInfo) {
const username = userInfo.username.trim()
const password = userInfo.password
const code = userInfo.code
const uuid = userInfo.uuid
return new Promise((resolve, reject) => {
login(username, password, code, uuid).then(res => {
setToken(res.token)
commit('SET_TOKEN', res.token)
resolve()
}).catch(error => {
reject(error)
})
})
},可以看到在这个基础上又封装了一个Promise(Vue的异步处理对象),目的是统一返回自定义的 Promise,使外部调用统一处理。然后调用了ruoyi-ui/src/api/login.js的登录方法:
export function login(username, password, code, uuid) {
const data = {
username,
password,
code,
uuid
}
return request({
url: '/login',
headers: {
isToken: false,
repeatSubmit: false
},
method: 'post',
data: data
})
}从前两章可以知道,此时前端就通过axios携带data,以post请求,路径为/login发送给后端了。
五、学习源码--登录(后端)
到了后端有3个步骤,都在 loginService.login 方法中实现:
1.校验验证码
public void validateCaptcha(String username, String code, String uuid)
{
boolean captchaEnabled = configService.selectCaptchaEnabled();
if (captchaEnabled)
{
// 如果 uuid 不为 null,则返回 uuid 本身。
// 如果 uuid 为 null,则返回第二个参数(这里是空字符串 "")。
String verifyKey = CacheConstants.CAPTCHA_CODE_KEY + StringUtils.nvl(uuid, "");
// 从缓存获取验证码
String captcha = redisCache.getCacheObject(verifyKey);
if (captcha == null)
{
// 异步写登录失败日志,提升登录风控能力
AsyncManager.me().execute(AsyncFactory.recordLogininfor(username, Constants.LOGIN_FAIL, MessageUtils.message("user.jcaptcha.expire")));
throw new CaptchaExpireException();
}
// 确保验证码只能使用一次
redisCache.deleteObject(verifyKey);
if (!code.equalsIgnoreCase(captcha))
{
// 异步写登录失败日志,提升登录风控能力
AsyncManager.me().execute(AsyncFactory.recordLogininfor(username, Constants.LOGIN_FAIL, MessageUtils.message("user.jcaptcha.error")));
throw new CaptchaException();
}
}
}其中,AsyncManager.me()返回一个全局唯一的异步任务管理器对象(采用类似“饿汉式单例”),负责调度异步任务。AsyncFactory.recordLogininfor(...)构建一个 TimerTask 对象(实现了 Runnable 接口),该任务封装了“将登录信息写入数据库和日志”的操作,包括 IP 地址、浏览器信息、操作结果等。.execute(task)将上面生成的 TimerTask 提交给 ScheduledExecutorService 线程池,常带延迟执行(默认大约 10 毫秒)。这样核心逻辑继续执行,日志记录由后台线程异步完成,不会拖慢响应速度。
2.校验用户名和密码
// 用户验证
Authentication authentication = null;
try
{
UsernamePasswordAuthenticationToken authenticationToken = new UsernamePasswordAuthenticationToken(username, password);
AuthenticationContextHolder.setContext(authenticationToken);
// 该方法会去调用UserDetailsServiceImpl.loadUserByUsername
authentication = authenticationManager.authenticate(authenticationToken);
}
catch (Exception e)
{
if (e instanceof BadCredentialsException)
{
AsyncManager.me().execute(AsyncFactory.recordLogininfor(username, Constants.LOGIN_FAIL, MessageUtils.message("user.password.not.match")));
throw new UserPasswordNotMatchException();
}
else
{
AsyncManager.me().execute(AsyncFactory.recordLogininfor(username, Constants.LOGIN_FAIL, e.getMessage()));
throw new ServiceException(e.getMessage());
}
}
finally
{
AuthenticationContextHolder.clearContext();
}
AsyncManager.me().execute(AsyncFactory.recordLogininfor(username, Constants.LOGIN_SUCCESS, MessageUtils.message("user.login.success")));
LoginUser loginUser = (LoginUser) authentication.getPrincipal();
recordLoginInfo(loginUser.getUserId());其中, UsernamePasswordAuthenticationToken 是 Spring Security 提供的一个 Authentication 实现,用于封装用户输入的用户名(principal)和密码(credentials)。
AuthenticationContextHolder.setContext(authenticationToken) 将这个认证请求放入上下文中,方便后续流程访问。Spring Security 默认使用 SecurityContextHolder 存储认证信息,它使用 ThreadLocal 机制,确保每次请求在同一个线程中可访问此上下文。这样做的目的是让认证流程安全且线程隔离,不会产生上下文泄漏。
AuthenticationManager 是 Spring Security 核心认证接口,只有一个方法 authenticate(Authentication),用于处理认证请求。
authenticate(authenticationToken) 的流程:
ProviderManager接收到UsernamePasswordAuthenticationToken;找到支持这种类型的
AuthenticationProvider(通常是DaoAuthenticationProvider);调用
UserDetailsServiceImpl.loadUserByUsername(username)从数据库加载用户详情;对比用户输入密码和数据库中存储的加密密码;
认证成功:返回一个包含用户信息和权限的新
Authentication对象(isAuthenticated()为true);
认证失败:抛出BadCredentialsException、DisabledException等异常。
AuthenticationContextHolder.clearContext() 作用是清除 Spring Security 在当前线程里的安全上下文(SecurityContext),确保之后不会发生信息泄漏或线程污染。
最后从认证结果中获取已认证的 LoginUser 对象(包含用户全部信息和权限)。调用 recordLoginInfo(userId) 方法,记录用户登录时间、登录 IP、登录设备类型等信息到用户表或日志。其中,AsyncManager记录的是登录日志,而recordLoginInfo 则记录的是用户登录信息(ip和时间等)。
3.生成token
public String createToken(LoginUser loginUser)
{
String token = IdUtils.fastUUID();
loginUser.setToken(token);
// 获取用户ip,系统,浏览器信息
setUserAgent(loginUser);
// 存储用户登录信息到redis,30min
refreshToken(loginUser);
// 这里用jwt
Map<String, Object> claims = new HashMap<>();
claims.put(Constants.LOGIN_USER_KEY, token);
claims.put(Constants.JWT_USERNAME, loginUser.getUsername());
return createToken(claims);
}这里调用了framework服务里的创建token方法,包含了jwt的工具,使用的依赖是:
<!-- Token生成与解析-->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
</dependency>六、学习源码--获取用户信息(前端)
在登录时,前端会发送一个 getInfo 的登录请求,我就来找一下这个请求是怎么发出的。
经过一番查找,在 src/permission.js 中的 beforeEach 方法中找到了:
router.beforeEach((to, from, next) => {
NProgress.start()
if (getToken()) {
to.meta.title && store.dispatch('settings/setTitle', to.meta.title)
/* has token*/
if (to.path === '/login') {
next({ path: '/' })
NProgress.done()
} else if (isWhiteList(to.path)) {
next()
} else {
if (store.getters.roles.length === 0) {
isRelogin.show = true
// 判断当前用户是否已拉取完user_info信息
store.dispatch('GetInfo').then(() => {
isRelogin.show = false
store.dispatch('GenerateRoutes').then(accessRoutes => {
// 根据roles权限生成可访问的路由表
router.addRoutes(accessRoutes) // 动态添加可访问路由表
next({ ...to, replace: true }) // hack方法 确保addRoutes已完成
})
}).catch(err => {
store.dispatch('LogOut').then(() => {
Message.error(err)
next({ path: '/' })
})
})
} else {
next()
}
}
} else {
// 没有token
if (isWhiteList(to.path)) {
// 在免登录白名单,直接进入
next()
} else {
next(`/login?redirect=${encodeURIComponent(to.fullPath)}`) // 否则全部重定向到登录页
NProgress.done()
}
}
})前端每个页面跳转之前都需要进入这个 beforeEach 方法里面,让我们接着看 store.dispatch('GetInfo') 里面的GetInfo,点进去就看见src/store/modules/user.js 里的GetInfo方法,里面有一个Promise异步调用,再进到该异步调用里的getInfo方法里,就可以看到配置跳转连接的地方了:
// 获取用户详细信息
export function getInfo() {
return request({
url: '/getInfo',
method: 'get'
})
}等获取到信息后就会把信息存储在Vuex里。
然后我们就可以去看后端是如何处理的。
七、学习源码--获取用户信息(后端)
在后端查找到了 SysLoginController 的getInfo方法:
@GetMapping("getInfo")
public AjaxResult getInfo()
{
LoginUser loginUser = SecurityUtils.getLoginUser();
SysUser user = loginUser.getUser();
// 角色集合
Set<String> roles = permissionService.getRolePermission(user);
// 权限集合
Set<String> permissions = permissionService.getMenuPermission(user);
if (!loginUser.getPermissions().equals(permissions))
{
loginUser.setPermissions(permissions);
tokenService.refreshToken(loginUser);
}
AjaxResult ajax = AjaxResult.success();
ajax.put("user", user);
ajax.put("roles", roles);
ajax.put("permissions", permissions);
// 默认密码检查:提示用户修改初始密码。
ajax.put("isDefaultModifyPwd", initPasswordIsModify(user.getPwdUpdateDate()));
// 密码过期检查:强制用户定期更新密码。
ajax.put("isPasswordExpired", passwordIsExpiration(user.getPwdUpdateDate()));
return ajax;
}用户登录时,Spring Security 的认证过滤器(如ruoyi-framework/src/main/java/com/ruoyi/framework/config/SecurityConfig.java)会调用
AuthenticationManager进行验证。验证成功后,生成包含用户信息的
Authentication对象,并存入SecurityContextHolder:SecurityContextHolder.getContext().setAuthentication(authentication);SecurityContextHolder默认使用ThreadLocal存储SecurityContext(内含Authentication对象),确保每个线程独立保存用户信息
Spring Security处理好后就开始获取用户的权限了,进入 getMenuPermission 方法内可以看见是怎么获取和分配用户权限的:
public Set<String> getMenuPermission(SysUser user)
{
Set<String> perms = new HashSet<String>();
// 管理员拥有所有权限
if (user.isAdmin())
{
perms.add("*:*:*");
}
else
{
List<SysRole> roles = user.getRoles();
if (!CollectionUtils.isEmpty(roles))
{
// 多角色设置permissions属性,以便数据权限匹配权限
for (SysRole role : roles)
{
if (StringUtils.equals(role.getStatus(), UserConstants.ROLE_NORMAL) && !role.isAdmin())
{
Set<String> rolePerms = menuService.selectMenuPermsByRoleId(role.getRoleId());
role.setPermissions(rolePerms);
perms.addAll(rolePerms);
}
}
}
else
{
perms.addAll(menuService.selectMenuPermsByUserId(user.getUserId()));
}
}
return perms;
}这段 getMenuPermission 方法是一个典型的基于 RBAC(角色-权限)模型的权限获取逻辑,核心目标是根据用户身份动态计算其菜单权限集合。
*:*:*是 RBAC 中的通配符权限,通常对应 Spring Security 的AllPermission设计,表示无限制访问用if判断是为了只处理状态为
ROLE_NORMAL(启用)的角色,避免禁用角色权限泄漏,然后通过menuService.selectMenuPermsByRoleId查询角色关联的权限码(如"system:user:add")。最后使用权限合并机制--用户最终权限是其所有角色权限的并集(perms.addAll)如果是未绑定角色的用户,则直接按用户ID查权限
八、学习源码--获取动态菜单路由(前端)
我们接着看 beforeEach 方法中的 GenerateRoutes :
// 生成路由
GenerateRoutes({ commit }) {
return new Promise(resolve => {
// 向后端请求路由数据
getRouters().then(res => {
// 1. 深拷贝后端返回的路由数据
const sdata = JSON.parse(JSON.stringify(res.data))
const rdata = JSON.parse(JSON.stringify(res.data))
// 2. 转换异步路由组件
const sidebarRoutes = filterAsyncRouter(sdata)
const rewriteRoutes = filterAsyncRouter(rdata, false, true)
// 3. 合并动态路由与静态路由
const asyncRoutes = filterDynamicRoutes(dynamicRoutes)
rewriteRoutes.push({ path: '*', redirect: '/404', hidden: true })
// 4. 动态添加路由到Vue Router实例
router.addRoutes(asyncRoutes)
// 5. 提交Vuex状态更新
commit('SET_ROUTES', rewriteRoutes)
commit('SET_SIDEBAR_ROUTERS', constantRoutes.concat(sidebarRoutes))
commit('SET_DEFAULT_ROUTES', sidebarRoutes)
commit('SET_TOPBAR_ROUTES', sidebarRoutes)
resolve(rewriteRoutes)
})
})
}注意:深拷贝(Deep Copy)是编程中一种对象复制方式,其核心在于创建完全独立的对象副本,包括所有层级的嵌套数据。深拷贝会递归复制原始对象的所有层级属性(包括嵌套对象、数组等),生成一个内存地址全新的对象。修改新对象不会影响原对象,两者完全隔离。
然后去到ruoyi-ui/src/api/menu.js的getRouters()方法里可以看到发送的请求路径。
根据后端返回的用户权限获取动态路由。
九、学习源码--获取动态菜单路由(后端)
查看ruoyi-admin/src/main/java/com/ruoyi/web/controller/system/SysLoginController.java中的getRouters方法,再进入 selectMenuTreeByUserId 方法中可以看到:
/**
* 根据用户ID查询菜单
*
* @param userId 用户名称
* @return 菜单列表
*/
@Override
public List<SysMenu> selectMenuTreeByUserId(Long userId)
{
List<SysMenu> menus = null;
if (SecurityUtils.isAdmin(userId))
{
// 管理员查询所有菜单
menus = menuMapper.selectMenuTreeAll();
}
else
{
// 普通用户按ID查询
menus = menuMapper.selectMenuTreeByUserId(userId);
}
return getChildPerms(menus, 0);
}
/**
* 根据父节点的ID获取所有子节点
*
* @param list 分类表
* @param parentId 传入的父节点ID
* @return String
*/
public List<SysMenu> getChildPerms(List<SysMenu> list, int parentId)
{
List<SysMenu> returnList = new ArrayList<SysMenu>();
for (SysMenu t : list) {
// 根据传入的某个父节点ID,遍历该父节点的所有子节点
if (t.getParentId() == parentId) {
recursionFn(list, t);
returnList.add(t);
}
}
return returnList;
}
/**
* 递归列表
*
* @param list 分类表
* @param t 子节点
*/
private void recursionFn(List<SysMenu> list, SysMenu t)
{
// 得到子节点列表
List<SysMenu> childList = getChildList(list, t);
t.setChildren(childList);
for (SysMenu tChild : childList)
{
if (hasChild(list, tChild))
{
recursionFn(list, tChild);
}
}
}
/**
* 得到子节点列表
*/
private List<SysMenu> getChildList(List<SysMenu> list, SysMenu t)
{
List<SysMenu> tlist = new ArrayList<SysMenu>();
Iterator<SysMenu> it = list.iterator();
while (it.hasNext())
{
SysMenu n = (SysMenu) it.next();
if (n.getParentId().longValue() == t.getMenuId().longValue())
{
tlist.add(n);
}
}
return tlist;
}这两段代码实现了基于用户权限的菜单树查询与树形结构转换,一步步看:
管理员路径:调用
menuMapper.selectMenuTreeAll()获取全量菜单(无需过滤)普通用户路径:调用
menuMapper.selectMenuTreeByUserId(userId),按用户角色动态过滤菜单(RBAC模型)树形结构生成 (
getChildPerms):
输入:遍历菜单列表,找到所有父节点ID匹配parentId的项(如顶层菜单),
输出:对每个匹配项调用recursionFn递归挂载子节点。递归挂载子树(
recursionFn)getChildList():遍历全表筛选当前节点的直接子节点(parentId = 当前节点ID)hasChild():判断子节点是否还有下级节点(代码中未展示,通常检查子节点列表非空)graph TD A[根节点] --> B[子节点1] A --> C[子节点2] B --> D[孙节点1] C --> E[孙节点2]还有优化方案(Map分组+递归(O(n))),但是时间关系不尝试了。
十、学习源码--用户管理(前端)
来到ruoyi-ui/src/views/system/user/index.vue,可以看到用户列表方法,查看负责加载数据的 listUser 方法可以得到访问后端链接是 /system/user/list
十一、学习源码--用户管理(后端)
通过链接查找可以找到获取用户列表的方法:
@PreAuthorize("@ss.hasPermi('system:user:list')")
@GetMapping("/list")
public TableDataInfo list(SysUser user)
{
startPage();
List<SysUser> list = userService.selectUserList(user);
return getDataTable(list);
}权限控制:在调用
list()方法前,通过 SpEL 表达式@ss.hasPermi('system:user:list')验证当前用户是否拥有system:user:list权限
自定义逻辑:@ss指向 Spring 容器中名为ss的 Bean(通常为自定义权限服务类),hasPermi是其内部定义的权限校验方法。
权限标识:system:user:list是权限标识符,对应系统中“用户列表查询”操作的权限码。startPage()是pageHelper结合mybatis做的分页,这段代码很陌生,所以着重看一下:TableSupport.buildPageRequest()从HttpServletRequest中解析分页参数(如pageNum、pageSize)public class PageUtils extends PageHelper { /** * 设置请求分页数据 */ public static void startPage() { PageDomain pageDomain = TableSupport.buildPageRequest(); Integer pageNum = pageDomain.getPageNum(); Integer pageSize = pageDomain.getPageSize(); String orderBy = SqlUtil.escapeOrderBySql(pageDomain.getOrderBy()); Boolean reasonable = pageDomain.getReasonable(); PageHelper.startPage(pageNum, pageSize, orderBy).setReasonable(reasonable); } /** * 清理分页的线程变量 */ public static void clearPage() { PageHelper.clearPage(); } }首先,
TableSupport.buildPageRequest()从HttpServletRequest中解析分页参数(如pageNum、pageSize),默认值通常为pageNum=1、pageSize=10。
然后,SqlUtil.escapeOrderBySql()对排序字段进行安全过滤,防止 SQL 注入(如过滤;或--等危险字符)。
接着从请求参数解析合理化开关(打开了的话reasonable就等于true),然后PageHelper.startPage(pageNum, pageSize, orderBy).setReasonable(true)修正前端传入的不合理分页参数(如超范围的页码或无效的页大小),确保用户始终获得有效的分页数据响应。比如说:PageHelper.startPage(-5, 10).setReasonable(true);最后实际执行的就是pageNum=1。
最后清理分页的线程变量,PageHelper 通过ThreadLocal<Page>存储分页参数,clearPage()调用LOCAL_PAGE.remove()移除当前线程的分页参数。这样做是因为若分页参数未被清理,可能导致后续非分页查询意外应用分页逻辑(如 SQL 被追加LIMIT)现在我们接着看
selectUserList的实现:@Override @DataScope(deptAlias = "d", userAlias = "u") public List<SysUser> selectUserList(SysUser user) { return userMapper.selectUserList(user); }@DataScope注解的重点在于--实现数据隔离的核心机制,是通过 动态 SQL 拼接 + AOP 切面 在运行时自动注入权限过滤条件。
此注解会被切面ruoyi-framework/src/main/java/com/ruoyi/framework/aspectj/DataSourceAspect.java拦截,获取当前用户和用户的全部权限,还有注解带上的别名,根据这些内容生成权限 SQL 片段,存入user.getParams().put("dataScope", "..."),然后去Mapper执行动态替换:<select id="selectUserList" parameterType="SysUser" resultMap="SysUserResult"> select u.user_id, u.dept_id, u.nick_name, u.user_name, u.email, u.avatar, u.phonenumber, u.sex, u.status, u.del_flag, u.login_ip, u.login_date, u.create_by, u.create_time, u.remark, d.dept_name, d.leader from sys_user u left join sys_dept d on u.dept_id = d.dept_id where u.del_flag = '0' <!-- 此处省略一大堆if判断 --> <!-- 数据范围过滤 --> ${params.dataScope} </select>比如当(部门ID=100, 用户ID=123),
SysUser参数对象中会包含权限条件:user.getParams().put("dataScope", "AND (d.dept_id = 100)");,到了mapper这就会把${params.dataScope}替换为AND (d.dept_id = 100)。最后是
return getDataTable(list),是一个用于封装分页响应数据的工具方法,其核心作用是将MyBatis分页查询结果转换为统一的响应结构。
十二、学习源码--部门树状图(前端)
在ruoyi-ui/src/api/system/dept.js中可以得到查询部门列表的请求链接,想要查看树状结构是如何实现的,可以查看ruoyi-ui/src/utils/ruoyi.js。
十三、学习源码--部门树状图(后端)
然后看看后端是怎么实现获取部门树列表的:
@PreAuthorize("@ss.hasPermi('system:user:list')")
@GetMapping("/deptTree")
public AjaxResult deptTree(SysDept dept)
{
return success(deptService.selectDeptTreeList(dept));
}
/**
* 查询部门树结构信息
*
* @param dept 部门信息
* @return 部门树信息集合
*/
@Override
public List<TreeSelect> selectDeptTreeList(SysDept dept)
{
List<SysDept> depts = SpringUtils.getAopProxy(this).selectDeptList(dept);
return buildDeptTreeSelect(depts);
}
/**
* 构建前端所需要下拉树结构
*
* @param depts 部门列表
* @return 下拉树结构列表
*/
@Override
public List<TreeSelect> buildDeptTreeSelect(List<SysDept> depts)
{
List<SysDept> deptTrees = buildDeptTree(depts);
return deptTrees.stream().map(TreeSelect::new).collect(Collectors.toList());
}
/**
* 构建前端所需要树结构
*
* @param depts 部门列表
* @return 树结构列表
*/
@Override
public List<SysDept> buildDeptTree(List<SysDept> depts)
{
List<SysDept> returnList = new ArrayList<SysDept>();
List<Long> tempList = depts.stream().map(SysDept::getDeptId).collect(Collectors.toList());
for (SysDept dept : depts)
{
// 如果是顶级节点, 遍历该父节点的所有子节点
if (!tempList.contains(dept.getParentId()))
{
recursionFn(depts, dept);
returnList.add(dept);
}
}
if (returnList.isEmpty())
{
returnList = depts;
}
return returnList;
}先从
selectDeptTreeList开始,使用SpringUtils.getAopProxy(this)获取代理对象,确保AOP生效(如事务、权限等),调用selectDeptList获取原始部门列表,再将结果转换为树形选择器结构然后是
buildDeptTreeSelect将部门树转换为树形选择器格式,调用buildDeptTree构建部门树,使用Java Stream将SysDept转换为TreeSelect(TreeSelect是前端树形选择器所需的数据结构)。接下来说明核心方法
buildDeptTree,当前部门的父ID不在部门ID集合中时(if (!tempList.contains(dept.getParentId()))),是顶级节点或者孤儿节点,直接进入递归并构建当前部门的子树。当没有找到任何根节点时,所有节点都有父节点(非树结构)或者循环引用导致找不到根节点,直接返回原始平面列表。